☢ 以下信息仅是个人笔记,不保证时效性,不保证准确度☢
☢ 以下信息仅是个人笔记,不保证时效性,不保证准确度☢
☢ 以下信息仅是个人笔记,不保证时效性,不保证准确度☢
Beats
以filebeat为例,这里我选择二进制方式
当然还有指标收集器:Merticbeat
简单原理
filebeat 通过 input 管理 harvesters,harvesters 负责逐行读取单个文件的内容,并将数据发送给 output。
filebeat 通过注册表来记录 harvesters 正在读取的文件位置,从而避免重复读取。因此,filebeat 重启的时候,始终会通过注册表得知最后一个已知的位置从而继续运行 harvesters。
filebeat 通过注册表来记录 harvesters 读取的每一行事件的传输状态,来确保事件不会丢失。若 filebeat 已将某个事件传递到 output ,但还未收到确认的时候就 down 掉,则 filebeat 会重发数据,这可能会出现重复数据。
💥应确保filebeat的日志处理速度大于日志的写入速度,或者日志轮转保留一定量的日志数量。如果日志文件写入磁盘的速度超过 FileBeat 可以处理的速度,或者在output不可用时删除了日志文件,数据有可能会丢失。在 Linux 上,FileBeat 也可能因为 inode 重用而跳过行。
安装
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation-configuration.html
mkdir -p /export/src && cd /export/src
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.15.1-linux-x86_64.tar.gz
tar xzvf filebeat-7.15.1-linux-x86_64.tar.gz
mv filebeat-7.15.1-linux-x86_64 ../filebeat && cd ..
cd filebeat
配置
# 添加配置文件
cat > filebeat.yml << EOF
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#filebeat.autodiscover:
# providers:
# - type: docker
# hints.enabled: true
filebeat.shutdown_timeout: 5s # Filebeat 在关闭时等待发布者完成发送事件的时间
# 注册表记录了收割机读取文件的信息以及读取的最后指针位置
close_removed: true # 开启状态下,如果文件被删除或者改名,则收割进程将立即关闭文件描述符并终止读取。反之,收割进程将会在完全读取完毕后,才会关闭文件描述符。(如果你要关闭这个选项,则 clean_removed 也需要关闭).
clean_removed: true # 只要注册表里的文件名在磁盘上找不到,则清除对应的注册表项。开启它(默认开启)可以一定程度上解决注册表过大。但这会有一个问题,当共享数据盘短时间内取消挂载并重新挂载,则注册表会重新注册文件,这将导致文件被重新读取发送(即重复读取).
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/secure-*
tags: ["syslog","secure"]
fields:
log_topic: zz.it.elk.syslog.secure
- type: log
enabled: true
paths:
- /export/logs/*.log
tags: ["apache","access"]
fields:
log_topic: zz.it.elk.apache.access
- type: log
enabled: true
paths:
- /export/logs/*.json
tags: ["apache","error"]
# keys_under_root可以让字段位于根节点,默认为false
json.keys_under_root: true
# 对于同名的key,覆盖原有key值
json.overwrite_keys: true
json.message_key: message
# 将解析错误的消息记录储存在error.message字段中
json.add_error_key: true
# 日志多行合并采集(配置的时候一定要顶格写)
# 匹配以{开头之后的数据,一直到下一个{之前
multiline.type: pattern
multiline.pattern: '^{'
multiline.negate: true
multiline.match: after
# 处理器:在output阶段之前,优化event
## ecs 字段删除
processors:
- drop_fields:
fields: ["ecs","input","agent","log"]
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["hadoop001:8123", "hadoop002:8123", "hadoop003:8123"]
username: elk
password: 123456
sasl.mechanism: SCRAM-SHA-256
# message topic selection + partitioning
# 一定要注意 log_topic 字段在事件中的位置
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
EOF
-
modules 定义了filebeat内置的针对不同程序的采集模块,默认后缀都是
.disabled,也就是不启用。关于各种模块的介绍,参考https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-modules.html。本文后面会有所介绍。
-
配置文件中有一个
${path.config},引用了配置path.config,在二进制部署中path.config就是二进制程序所在的目录。关于filebeat程序内诸如路径的配置,参考https://www.elastic.co/guide/en/beats/filebeat/current/directory-layout.html#directory-layout
-
reload.enabled表示开启动态重载,开启之后,每间隔reload.period时间,Beats就会重载一次path指定的配置.可以从https://www.elastic.co/guide/en/beats/filebeat/current/_live_reloading.html中获取. -
filebeat.inputs中我们添加了额外的tags,这个tags字段会出现在事件(json)的根下,因此可以方便的通过tags来动态的生成ES索引名. -
%{[fields.log_topic]} 调用事件字段,仅在output阶段使用
多行匹配配置
# 日志多行合并采集(配置的时候一定要顶格写)
# 匹配以{开头之后的数据,一直到下一个{之前
multiline.type: pattern
multiline.pattern: '^{'
multiline.negate: true
multiline.match: after
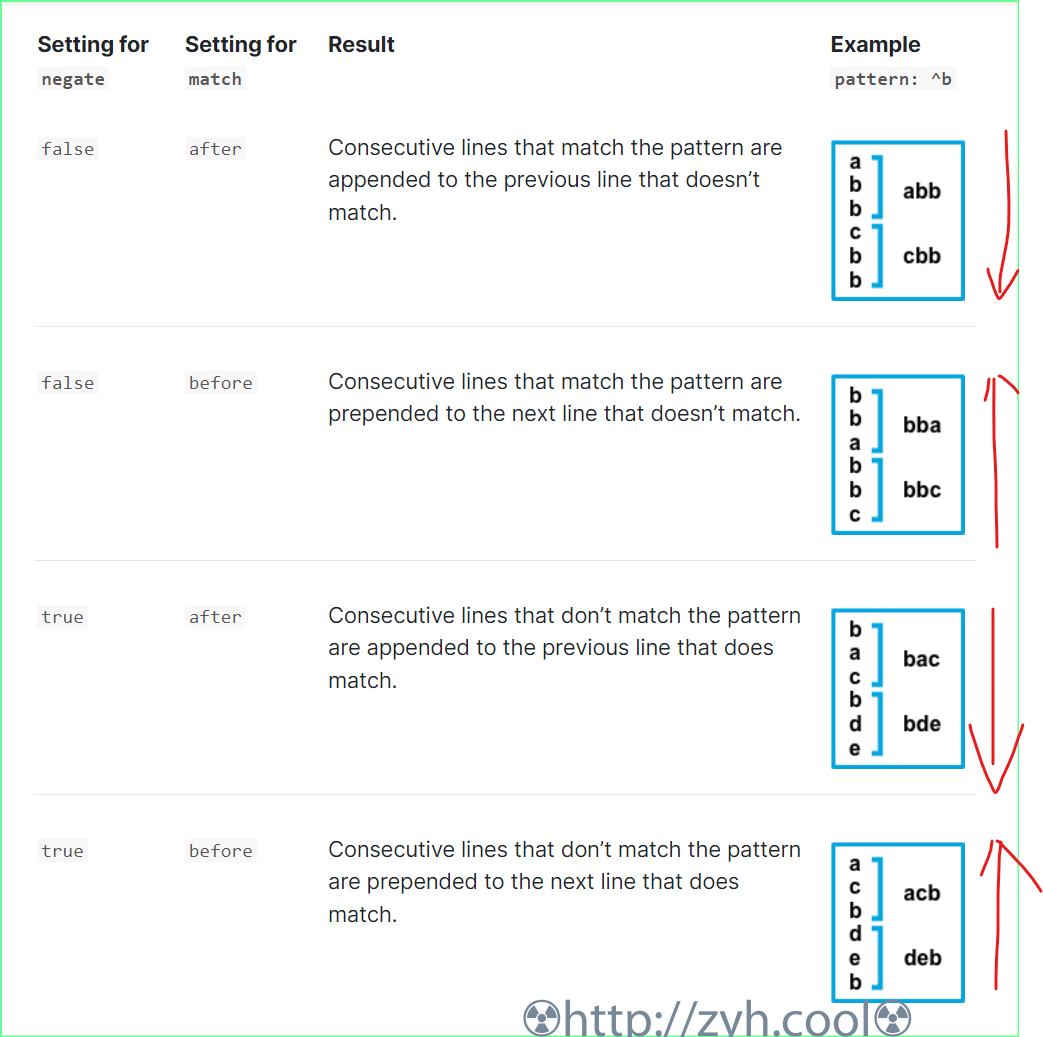
下图表示:
例1:匹配(false)b开头的多行,直到遇到多行之后(after)的某行c不匹配,则不匹配行c就是事件起始点。
例2:匹配(false)b开头的多行,直到遇到多行之前(before)的某行a不匹配,则不匹配行a就是事件重点。
例3:不匹配(true)b开头的多行,直到遇到多行之后(after)的某行b匹配,则匹配行b就是事件起始点。
例4:不匹配(true)b开头的多行,直到遇到多行之前(before)的某行b匹配,则匹配行b就是事件重点。
processors处理器配置
https://www.elastic.co/guide/en/beats/filebeat/current/filtering-and-enhancing-data.html
作用是在output阶段之前,优化event,例如添加字段、删除字段等。
如果存在多个处理器,按定义顺序执行。
filebeat 内置了众多处理器。
add_kubernetes_metadata 处理器
这个处理器给每个事件附加pod元数据。附加的元数据有:
- Pod Name
- Pod UID
- Namespace
- Labels
如何给每个事件附加对应的pod元数据,依赖于两个构造字段:
- Indexers
- Matchers
Indexers 索引器:通过 indexer 构建一个标识符作为事件分类后的索引;
container索引器,使用Pod下的容器 ID 作为标识符构建索引。
Matchers 匹配器:作用是以 matcher 构建一个和 indexer 标识符相同的查询 key,从而过滤 input 事件。
logs_path匹配器,基于 pod uid 或者 container id 作为查询 key 过滤 input 事件,并将事件关联到对应的标识符索引下。
这样,对应标识符索引下的事件,都会附加上此索引标识符对应pod的元数据。
简单来看, Indexer 的值应该与 Matcher 的查询 key 保持一致。
举例:
processors: - add_kubernetes_metadata:
in_cluster: true # filebeat 位于集群内
default_indexers.enabled: false
default_matchers.enabled: false
indexers:
- container:
matchers:
- logs_path:
resource_type: 'container'
logs_path: '/var/log/containers/'
- drop_fields:
fields: ["host.name"]
ignore_missing: true
- copy_fields:
fields:
- from: kubernetes.node.name
to: host.name
fail_on_error: false
ignore_missing: true
add_kubernetes_metadata 可能出现的故障
💥启用add_kubernetes_metadata报错,根据提示给filebeat添加NODE_NAME环境变量
add_kubernetes_metadata/kubernetes.go:177 Couldn't dis
cover Kubernetes node: %!w(*errors.fundamental=&{kubernetes: Node could not be discovered with any known method. Consider setting env var NODE_NAME 0xc00056
0ae0}) {"libbeat.processor": "add_kubernetes_metadata"}
containers:
- name: filebeat
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
💥add_kubernetes_metadata无法通过system:serviceaccount:kube-system:default获取api,根据提示创建新的SA对象。
reflector.go:138] pkg/mod/k8s.io/[email protected]/tools/cache/reflector.go:167: F
ailed to watch *v1.Node: failed to list *v1.Node: nodes "k8s01" is forbidden: User "system:serviceaccount:kube-system:default" cannot list resource "nodes"
in API group "" at the cluster scope
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
app: filebeat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
app: filebeat
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
output
output用来指定filebeat读取的数据输出到哪。
💥不同版本的filebeat能支撑的output插件的参数都可能不同。例如老版本的 filebeat 的 output.kafka.sasl.mechanism 支撑就有问题。
output负载均衡
仅支持redis/logstash/es,kafka是内部自身负载
output.logstash:
hosts: ["localhost:5044", "localhost:5045"]
loadbalance: true
worker: 2
不开启loadbalance,主机列表里随机选一个作为输出,若故障就切换另一个。
开启loadbalance,将事件平衡发送到主机列表,具体逻辑官网没说。
测试 output 是否可用
./filebeat test output
启动
- 测试数据(一定不要针对大文件使用)
./filebeat -e -d "*"
# -e 表示关闭文件日志,输出到控制台
# -d 表示开启debug,后面"*"指输出所有debug
如果上面的命令有事件输出,则说明filebeat配置基本无误,如果没有实际数据对象输出,则直接检查filebeat配置或者日志文件本身。
默认情况下,filebeat 的每一个事件都会包含以下事件字段:
{ ... "@metadata": { "beat": "filebeat", "version": "7.15.1" } }
- 后台启动
nohup ./filebeat & 2>&1
ℹ️ 启动之后,会在${home.config}/data下生成注册表。注册表不能随意删除,删除意味着filebeat无法确定是否已读过文件,这会导致数据重复导入.
模块化
除了玩家自定义output,并搭配logstash的pipeline进行事件过滤转换。Beats组件一般还内置了一些通用场景的模块,这些模块已经包含了对应的默认配置,elasticsearch的ingest pipeline、索引模板以及kibana仪表,当你开启这些模块,Beats就可以自动将这些对象帮你创建好。
详情参见:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-modules.html
ℹ️模块的功能要想使用,output必须是elasticsearch,否则你即便启用,也无法安装.
官方CSDN也有一个博文,进行了使用简介 https://elasticstack.blog.csdn.net/article/details/109178666
现在,以采集系统日志为例.
ℹ️ 模块的采集可以单独用一个filebeat去跑。
在你执行下面的操作之前,请先确认两个条件:
- filebeat的output是Elasticsearch
- filebeat配置了kibana地址
首先,在kibana中创建图表,在elasticsearch中创建索引管理模板
./filebeat setup --dashboards --index-management
其次,开启模块
./filebeat modules enable system
然后,在elasticsearch中创建ingest pipeline
./filebeat setup --pipelines --modules system
此时,你可以在kibana后台找到
- 索引生命周期策略:filebeat
- 索引模式:filebeat-*
- 各种dashboard
- 以及ingest pipeline
ℹ️模块默认创建的索引都是filebeat-xxx,因此索引模式也是 filebeat-*,其 dashboard 数据设置的时候通过内置的字段来区分,例如system是通过 event.dataset:system.syslog 过滤.
最后,针对开启的模块,配置相关文件。默认这些文件都在 models.d,在没有 enable 的时候,文件后缀都是 disabled。
# Module: system
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.x/filebeat-module-system.html
- module: system
syslog:
enabled: true
var.paths: ["/path/to/log/syslog*"]
auth:
enabled: true
var.paths: ["/path/to/log/auth.log*"]
最后启动filebeat,查看数据是否有录入
./filebeat -e -d "*"
ℹ️因为通过模块创建的默认索引名字都是 filebeat-开头的,所以为了避免索引模式匹配到其它索引,建议非模块创建的索引名不以Beats组件名开头.
如果使用模块的时候,filebeat.output 指向了 logstash,那么logstash.output应该参照如下配置
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => "https://myEShost:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
user => "elastic"
password => "secret"
}
} else {
elasticsearch {
hosts => "https://myEShost:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
user => "elastic"
password => "secret"
}
}
ℹ️pipeline => “%{[@metadata][pipeline]}” 确保了 logstash.output 可以正确的找到 elasticsearch 中的 ingest pipeline.
遇到的问题点
- ⚠️filebeat读取的文件,一定要有行结尾符,否则将无法载入。
[root@es logs]# file 16033741222_2021_11_04_09_33_23_1703_15_1.6.13.json
16033741222_2021_11_04_09_33_23_1703_15_1.6.13.json: ASCII text, with very long lines, with no line terminators
上述文件中,通过file指令可以看到提示with no line terminators
-
⚠️模块并不能适配所有情况,例如system模块读取centos的auth级别日志(secure)就无法适配dashboard,可能只适配ubuntu的日志。
-
⚠️filebeat当前的output.logstash插件无法实现根据fields字段来动态选择管道.
-
Dropping event: no topic could be selectedoutput.kafka 中 topic 定义的变量有问题。