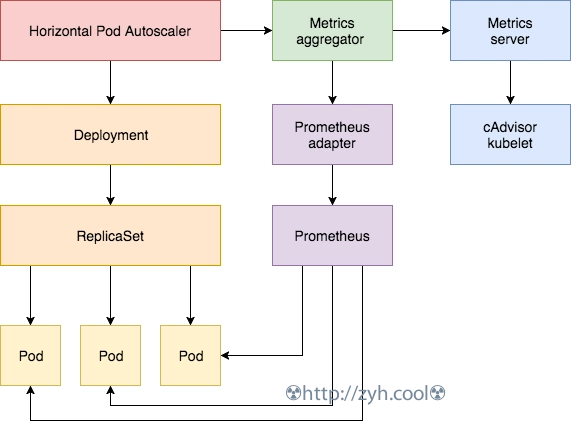
原理
除了基于 CPU 和内存来进行自动扩缩容之外,我们还可以根据自定义的监控指标来进行。这个我们就需要使用 Prometheus Adapter,Prometheus 用于监控应用的负载和集群本身的各种指标,Prometheus Adapter 可以帮我们使用 Prometheus 收集的指标并使用它们来制定扩展策略,这些指标都是通过 APIServer 暴露的,而且 HPA 资源对象也可以很轻易的直接使用。
结构图
待监控的demo
👙这个demo通过业界约定俗称的注解暴漏metrics接口给prometheus,因此prometheus需要先配置kubernetes_sd_config自动发现的endpoints角色功能。
hpa-prome-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-prom-demo
spec:
selector:
matchLabels:
app: nginx-server
template:
metadata:
labels:
app: nginx-server
spec:
containers:
- name: nginx-demo
image: cnych/nginx-vts:v1.0
resources:
limits:
cpu: 50m
requests:
cpu: 50m
ports:
- containerPort: 80
name: http
---
apiVersion: v1
kind: Service
metadata:
name: hpa-prom-demo
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/status/format/prometheus"
spec:
ports:
- port: 80
targetPort: 80
name: http
selector:
app: nginx-server
type: NodePort
在这个demo中,nginx暴漏了一个请求总数的指标nginx_vts_server_requests_total ,我们通过这个指标来扩缩。
检查暴露指标
curl http://10.200.16.101:30233/status/format/prometheus
prometheus-adapter
我们将 Prometheus-Adapter 安装到集群中,并通过 Prometheus-Adapter 配置规则来查询 Prometheus 数据从而跟踪 Pod 的请求。
我们可以将 Prometheus 中的任何一个指标都用于 HPA,但是前提是你得通过查询语句将它拿到(包括指标名称和其对应的值)。
规则流程
Prometheus-Adapter 的官方文档:
https://github.com/kubernetes-sigs/prometheus-adapter/blob/master/docs/config.md
发现Discovery:发现基础指标
关联Association:将基础指标中的标签与k8s的资源对应起来
重命名Naming:构建HPA所需要的查询指标名
查询指标语句Querying:编写HPA所需要的指标数据查询语句,它是一个 go 模板
规则示例
定义一个pod级别的qps指标,目的是让hpa监视的pod的qps超过阈值的时候,就进行扩容,低于阈值的时候就缩容。
rules:
- seriesQuery: "nginx_vts_server_requests_total"
seriesFilters: []
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name: # 构建新的指标名 nginx_vts_server_requests_per_second
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>))
👙上述规则,对应规则流程的四个部分:
第一个部分是发现Discovery: seriesQuery,获取 nginx 的请求总数
第二个部分是关联Association:resources ,关联指标里的 pod_name 和 namespace 标签到 k8s 资源
第三个部分是重命名Naming:name,构建HPA查询指标名 nginx_vts_server_requests_per_second
第四个部分是查询指标语句Querying:metricsQuery,编写 nginx_vts_server_requests_per_second 所需的 PromQL
更详细的解析:
-
seriesQuery 就是 PromQL 语句,不过这个是基础指标。
-
resources 是将 prometheus 的指标与 k8s 的资源进行关联。
-
- overrides 下的 namespace 和 pod_name 是 prometheus 里面指标的标签名。因此这里需要根据 prometheus 查询的指标数据来填写。
- overrides.<指标标签>.resource 下的 namespace 和 pod 是与<指标标签>对应的 k8s 对象类型。
-
metricsQuery
-
- <<.Series>> 指的就是 nginx_vts_server_requests_total
- <<.LabelMatchers>> 作用根据 resources 的资源关联,从而在进行查询 k8s 对象暴漏的指标时,自动的将k8s对象信息代入到查询语句指标标签中。例如在例子中的 demo pod 名叫 hpa-prom-demo,位于namespace中,则这里的语句转换后就是 nginx_vts_server_requests_total{pod_name=“hpa-prom-demo-xxx”, namespace=“default”}
- <<.GroupBy>> 根据 resources 指定指标标签进行分组,例如: pod_name
部署
添加 repo,拉取 chart
👙prometheus-community repo 下有很多 chart
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
$ helm pull --untar prometheus-community/prometheus-adapter
$ cd prometheus-adapter
构建 helm hpa-prome-adapter-values.yaml
rules:
default: false
custom:
- seriesQuery: "nginx_vts_server_requests_total"
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>))
prometheus:
url: http://thanos-querier.kube-mon.svc.cluster.local
安装
$ helm upgrade --install prometheus-adapter -f hpa-prome-adapter-values.yaml --namespace monitor .
NAME: prometheus-adapter
LAST DEPLOYED: Mon Mar 29 18:52:44 2021
NAMESPACE: kube-mon
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
prometheus-adapter has been deployed.
In a few minutes you should be able to list metrics using the following command(s):
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1
校验规则
prometheus-adapter 会创建一个 APIService 类型:v1beta1.custom.metrics.k8s.io
通过这个 APIService 接口,查询构建的规则以及指标数据都会转到 prometheus-adapter 的 svc 对象。
➜ prometheus-adapter git:(main) ✗ kubectl get --raw="/apis/custom.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": []
}
👙如上,输出结果,就是服务正常,但是规则没生效。这个常见于规则流程中的 Association 资源关联有问题,需要检查规则中资源关联的 promeheus 指标标签是否存在。
正确的输出
➜ prometheus-adapter git:(main) ✗ kubectl get --raw="/apis/custom.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "pods/nginx_vts_server_requests_per_second",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "namespaces/nginx_vts_server_requests_per_second",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
通过APIService获取指标
➜ prometheus-adapter git:(main) ✗ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_vts_server_requests_per_second" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/nginx_vts_server_requests_per_second"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "hpa-prom-demo-bbb6c65bb-zbmzd",
"apiVersion": "/v1"
},
"metricName": "nginx_vts_server_requests_per_second",
"timestamp": "2022-05-02T04:12:45Z",
"value": "266m",
"selector": null
}
]
}
👙这里 value: 266m 指的是 qps:0.266
HPA
配置示例
监视 deployment/hpa-prom-demo 的所有 pod,当所有的 pod 的 nginx_vts_server_requests_per_second 指标超出阈值或者低于阈值的时候,就进行扩缩容。
# hpa-prome.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-custom-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-prom-demo
minReplicas: 2
maxReplicas: 5
metrics:
- type: Pods
pods:
metric:
name: nginx_vts_server_requests_per_second
target:
type: AverageValue
averageValue: 10 # 或者用 10000m
# m 除以 1000
# target 500 milli-requests per second,
# which is 1 request every two seconds
# averageValue: 500m
👙需要注意的是 apiVersion 版本。自定义HPA需要用v2版本。通过命令查询版本:
kubectl api-versions | grep autoscaling
测试命令
死循环访问监控demo
➜ kube-prometheus-myself git:(main) ✗ while true; do wget -q -O- http://10.200.16.101:30233; done
测试结果
➜ kube-prometheus-myself git:(main) ✗ kubectl describe hpa nginx-custom-hpa
Name: nginx-custom-hpa
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Mon, 02 May 2022 14:09:46 +0800
Reference: Deployment/hpa-prom-demo
Metrics: ( current / target )
"nginx_vts_server_requests_per_second" on pods: 266m / 10
Min replicas: 2
Max replicas: 5
Deployment pods: 2 current / 2 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric nginx_vts_server_requests_per_second
ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 25m horizontal-pod-autoscaler New size: 2; reason: Current number of replicas below Spec.MinReplicas
Normal SuccessfulRescale 7m28s horizontal-pod-autoscaler New size: 3; reason: pods metric nginx_vts_server_requests_per_second above target
Normal SuccessfulRescale 58s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
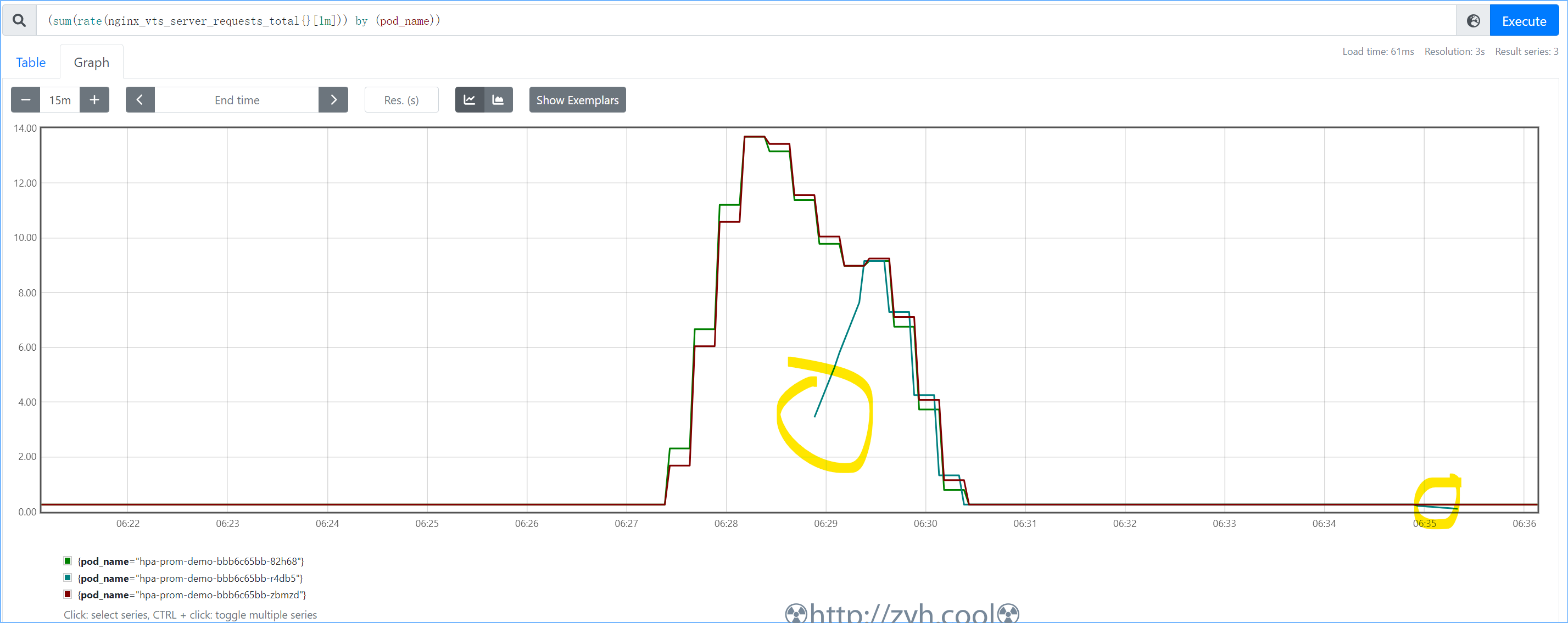
使用查询语句(sum(rate(nginx_vts_server_requests_total{}[1m])) by (pod_name))观察Prometheus状态