前言
pod 可以说是 k8s 的基础单元. 我觉得可以类比云环境的ecs/ec2这一类的基本计算单元.而 pod 上运行的容器, 可以类比为ecs/ec2上的app程序.
你总能在k8s的各类资源中找到云环境对应的资源影子. 如果你用过GCP,你会更有这种感觉.
https://kubernetes.io/docs/concepts/workloads/pods/
Pod与容器
一个pod可以拥有多个容器。
pod 内包含多个容器,所以多个容器共享以下资源。
-
PID命名空间: pod内的进程能互相看到PID
-
网络命名空间: pod中的多个容器共享一个ip (唯一)
-
IPC命名空间: pod中的多个容器之间可以互相通信
-
UTS命名空间: pod中的多个容器共享一个主机名 (唯一)
-
存储卷: pod多个容器可以共同访问pod定义的存储卷
另外,Pod可以包含一个init的特殊容器,它始终首先运行。
若pod只有一个容器,那么pod就是一个包装器
若pod有多个容器,则一般主容器提供服务;边车/挂斗/附属容器提供额外功能,例如刷新主容器的文件,收集日志。
ℹ️上述的功能的实现基于pod内的容器共享网络命名空间和存储空间.

如果你玩过星际争霸,那么应该知道一个人族建筑物,总是会有一个附属建筑物,它很小,但提供了主建筑物所需的科技。
因此,除非你两个容器必须放在一起,否则你应该用多个单容器pod.
Pod与负载控制器
生产环境中,pod 一般不单独使用,因为单独使用意味着没有高可用,且难以管理。k8s建议 pod 要始终和负载控制器一起使用。负载控制器可以批量创建pod。
k8s将负载控制器主要分为三种:
- Deployment 无状态 https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
- StatefulSet 有状态 https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
- DaemonSet 守护态 https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/
还有CronJob、Jobs任务类型的.
负载控制器需要依托于镜像模板创建 pod 和依托于缩放规则控制 pod 数量。
镜像模板即 pod 模板(pod template).
负载控制器 - Pod模板
一个构建nginx的例子
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
如何寻找最合适的kind所属的apiVersion
在这里可能有人不知道如何选择apiVersion。你可以通过kubectl api-versions来找到kind所属的apiGroup,然后再通过
kubectl get --raw “/apis” 的输出找 preferredVersion。
➜ kubectl api-resources | grep deployment
deployments deploy apps/v1 true Deployment
➜ kubectl get --raw "/apis"|jq '.groups[]|select(.name=="apps")'
{
"name": "apps",
"versions": [
{
"groupVersion": "apps/v1",
"version": "v1"
}
],
"preferredVersion": {
"groupVersion": "apps/v1",
"version": "v1"
}
}
如上命令所示,在我的k8s版本中kind: Deployment的最合适apiVersion是apps/v1
pod 存储
这是一个大问题. 如果你想真正的使用k8s的pod资源, 那么需要先看这一部分的内容.
简单来说, 存储资源主要分网络和本地两大类.
-
本地 用于临时或者特殊环境. 就如同云服务中的【存储类节点】里的那种本地盘, 它不可靠. 因为pod本身默认是不强制绑定某个节点的,因此如果你pod异常了,那么它有可能重建的时候漂移到其它节点.此时你如果用本地盘,那么数据将丢失。
-
网络 可以对接的有云服务厂家的存储资源,也可以对接自建的nfs这一类网络存储。
细致的说明, 参考官方文档https://kubernetes.io/docs/concepts/storage/
pod 网络
鉴于前面提到的pod类同于ecs/ec2. 因此. pod中的容器就如同ecs/ec2里的app一样,都有相同的ip, 端口范围, 主机名.
k8s的网络基于各种插件.每一种插件的实现详情见官网. https://kubernetes.io/docs/concepts/cluster-administration/networking/#how-to-implement-the-kubernetes-networking-model
如果你是本地搭建, 那么常用的插件是Flannel. 如果你是在云服务上搭建,那么建议使用云服务已有的k8s服务.
如果你必须在云服务上自己搭建,那么aws/azure/gcp都有对应的网络插件.它可以让你在k8s中结合使用云服务的网络组件.
当然你依然可以用 flannel 网络插件。
静态pod
特点:
- 永远运行在固定节点
- 由所在节点的kubelet管理,但只负责保活,即pod崩溃重生
- kubelet会让apiserver创建一个镜像pod,便于可以通过kubectl查询到静态pod
配置:
- 存放在 /etc/kubernetes/manifests 当采用kubeadm安装的时候,一般位于此目录。具体需要去看kubelet配置。
- 配置本身可以按照标准pod方式来创建
检测:
- kubelet会定期检测配置目录加载配置创建/重建pod
当你通过kubeadm创建的时候,那么k8s的几个重要组件均会以静态pod的方式在master节点上创建,你可以在/etc/kubernetes/manifests/这里找到他们的配置
➜ ll /etc/kubernetes/manifests/
total 16
-rw------- 1 root root 1848 Aug 25 16:28 etcd.yaml
-rw------- 1 root root 2709 Aug 25 16:28 kube-apiserver.yaml
-rw------- 1 root root 2564 Aug 25 16:33 kube-controller-manager.yaml
-rw------- 1 root root 1120 Aug 25 16:33 kube-scheduler.yaml
容器生命周期
- waiting,一般对应Pod的pending阶段
- running,容器运行OK
- terminated,容器退出
Pod-生命周期
Pod启动、终止中涉及到的各个组件。
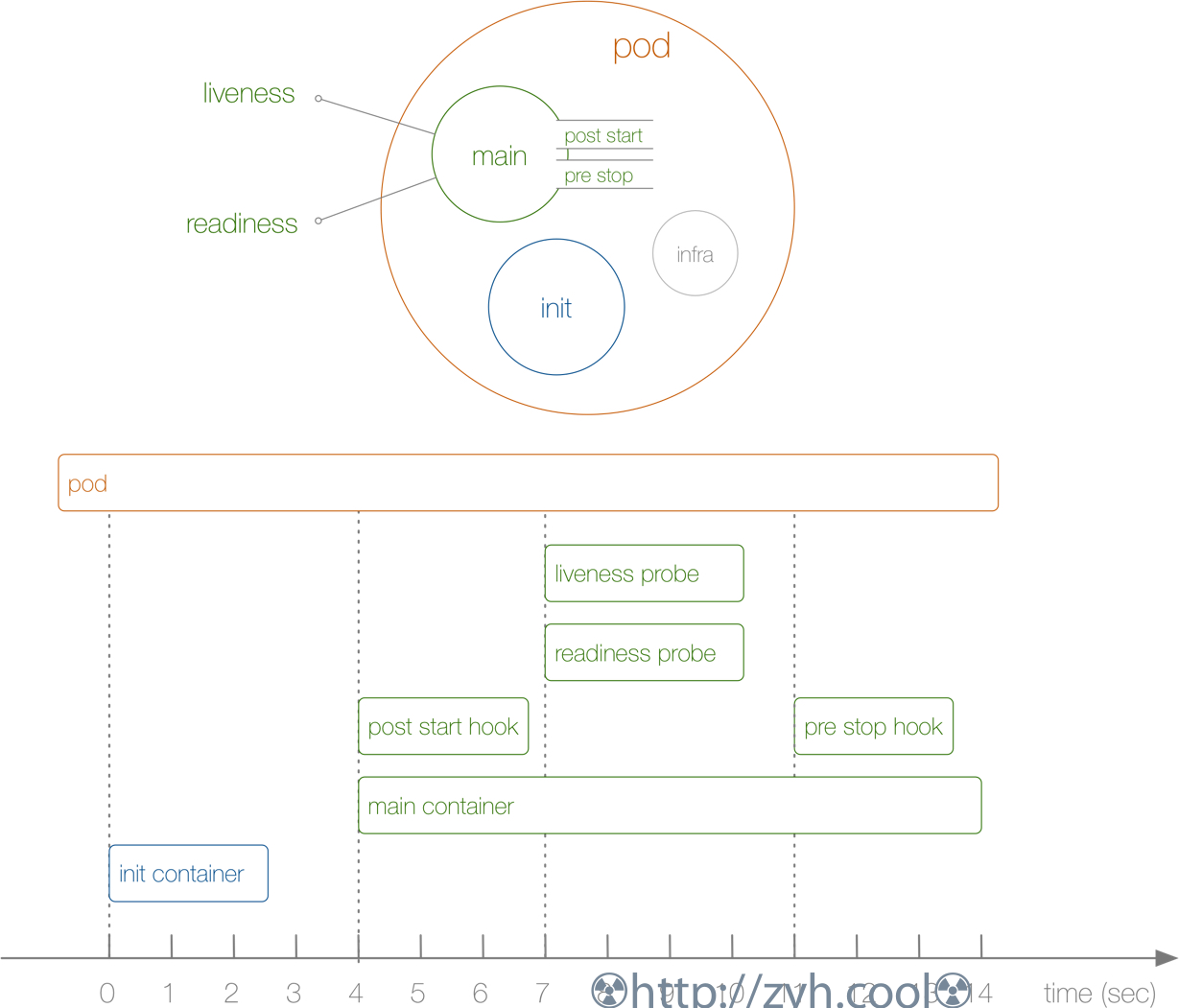
pod生命周期状态包含5个状态:
- pending,调度时间和拉取容器镜像时间,容器均处于waiting状态
- running,pod里所有容器都已经创建,且至少一个容器处于启动、重启、running状态
- failed,pod里的容器全退出,有部分容器以非0状态进入terminated状态
- succeeded,pod里的容器全部以0状态进入terminated状态,并且不会再重启
- unknown,pod所在节点和主节点之间失联,不过这种状态会因k8s的策略转为failed状态
pod是通过uid来鉴别,而不是pod名,pod被替换时名称可以不变。
重启策略
https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#lifecycle
pod重启的启示间隔时间是10s,成指数上涨,但不超过5分钟。一旦重启成功且运行10分钟,则重置为10s。
pod.spec中定义:restartPolicy:Always、Nerver、OnFailure
从实际使用来说:
- Job重启策略通常是:OnFailure或者Nerver
- ReplicaSet、DaemonSet、Deployment重启策略通常是:Always
运行状况
通过kubectl describe pod/<pod_name>查看Conditions字段条件
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Ready为True,即表示【应该】被加入到svc的端点列表中。
但极端情况下有可能因为其它服务没准备好,导致及时Pod的Ready为True,svc也无法正常的转发流量到Pod。
这种行为,可能在滚动更新的时候,会导致丢数据。
针对上述问题,kubernetes允许在上面4个默认状态的基础上自定义就绪状态类型。
https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/#pod-readiness-gate
终止流程
https://kubernetes.io/zh/docs/concepts/workloads/pods/pod-lifecycle/#pod-termination
-
Apiserver拿到删除请求、Apiserver更新pod状态,转为
Terminating。默认Pod有30 秒优雅终止时间。 -
kubelet推送preStop事件到容器中执行,如果设置了preStop的话
-
kubelet通过
container runtime发送TERM信号(kill-14)给每个容器中pid为1的进程号,并同时将pod从svc端点中剥离。- 如果容器在30秒内没有停止成功,则kubelet会发送SIGKILL信号(kill -9)给容器,强行杀掉。
-
容器关闭状态转为Terminated,Apiserver将Pod删除。
- 2和3是并行的,并且执行时间取决于Pod终止宽限期
terminationGracePeriodSeconds- kubectl 添加
--grace-period=0 --force可以立即删除Pod
ℹ️失败的pod状态会根据kube-controller-manager 参数 terminated-pod-gc-threshold阈值设置保存一定数量。默认这个值是12500,不清楚为何设置这么高。https://github.com/kubernetes/kubernetes/pull/79047这是一个被驳回的修正,它提议设置为500。
容器Terminated
通过下方命令可以查找Terminated的原因。
kubectl get pod -o go-template='{{range.status.containerStatuses}}{{"Container Name: "}}{{.name}}{{"\r\nLastState: "}}{{.lastState}}{{end}}' <pod_name:simmemleak>
simmemleak
Container Name: simmemleak
LastState: map[terminated:map[exitCode:137 reason:OOM Killed startedAt:2015-07-07T20:58:43Z finishedAt:2015-07-07T20:58:43Z containerID:docker://0e4095bba1feccdfe7ef9fb6ebffe972b4b14285d5acdec6f0d3ae8a22fad8b2]]
Downward-API
👙需要注意的是,Downward API 能够获取到的信息,一定是 Pod 里的容器进程启动之前就能够确定下来的信息。而如果你想要获取 Pod 容器运行后才会出现的信息,比如,容器进程的 PID,那就肯定不能使用 Downward API 了,而应该考虑在 Pod 里定义一个 sidecar 容器来获取了。
其支持的字段有:
1. 使用 fieldRef 可以声明使用:
spec.nodeName - 宿主机名字
status.hostIP - 宿主机IP
metadata.name - Pod的名字
metadata.namespace - Pod的Namespace
status.podIP - Pod的IP
spec.serviceAccountName - Pod的Service Account的名字
metadata.uid - Pod的UID
metadata.labels['<KEY>'] - 指定<KEY>的Label值
metadata.annotations['<KEY>'] - 指定<KEY>的Annotation值
metadata.labels - Pod的所有Label
metadata.annotations - Pod的所有Annotation
2. 使用 resourceFieldRef 可以声明使用:
容器的 CPU limit
容器的 CPU request
容器的 memory limit
容器的 memory request
环境变量方式
通过Downward API 获取Pod信息并存入到环境变量中,然后在容器里打印出来。
# env-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: env-pod
namespace: kube-system
spec:
containers:
- name: env-pod
image: busybox
command: ["/bin/sh", "-c", "env"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volume卷方式
将Pod的metadata.labels和metadata.annotations以 labels 和 annotations 文件方式挂载到容器里的 /etc/podinfo 目录下。
# volume-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: volume-pod
namespace: kube-system
labels:
k8s-app: test-volume
node-env: test
annotations:
own: youdianzhishi
build: test
spec:
volumes:
- name: podinfo
downwardAPI:
items:
- path: labels
fieldRef:
fieldPath: metadata.labels
- path: annotations
fieldRef:
fieldPath: metadata.annotations
containers:
- name: volume-pod
image: busybox
args:
- sleep
- "3600"
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
➜ ~ kubectl exec -it volume-pod /bin/sh -n kube-system
/ # ls /etc/podinfo/
..2019_11_13_09_57_15.990445016/ annotations
..data/ labels
/ # cat /etc/podinfo/labels
k8s-app="test-volume"
/ # cat /etc/podinfo/annotations
build="test"
kubectl.kubernetes.io/last-applied-configuration="{\"apiVersion\":\"v1\",\"kind\":\"Pod\",\"metadata\":{\"annotations\":{\"build\":\"test\",\"own\":\"youdianzhishi\"},\"labels\":{\"k8s-app\":\"test-volume\",\"node-env\":\"test\"},\"name\":\"volume-pod\",\"namespace\":\"kube-system\"},\"spec\":{\"containers\":[{\"args\":[\"sleep\",\"3600\"],\"image\":\"busybox\",\"name\":\"volume-pod\",\"volumeMounts\":[{\"mountPath\":\"/etc/podinfo\",\"name\":\"podinfo\"}]}],\"volumes\":[{\"downwardAPI\":{\"items\":[{\"fieldRef\":{\"fieldPath\":\"metadata.labels\"},\"path\":\"labels\"},{\"fieldRef\":{\"fieldPath\":\"metadata.annotations\"},\"path\":\"annotations\"}]},\"name\":\"podinfo\"}]}}\n"
kubernetes.io/config.seen="2019-11-13T17:57:15.320894744+08:00"
kubernetes.io/config.source="api"
注意点
- pod.spec.containers.ports 这里只是一个容器端口的信息公告,哪怕不设定,容器内程序的端口也会暴露。也就是说,如果你容器是nginx,其端口是80。而哪怕你这里设置的 pod.spec.conntainers.port.containerPort 是8080,则实际暴露的依然是80。