简介
logstash 使用inputs接收创建数据,filters过滤修改数据,outputs输出数据。三种动作均通过插件实现。
其中,inputs和outputs支持将codecs编码器作为自身的一部分。
inputs
inputs负责创建摄入管道(pipeline),每一个管道根据插件类型来决定是客户端还是服务端。
例如,beats插件,通常是服务端,接收beats客户端发过来的数据。此时,logstash.input开启一个服务端端口作为监听端口,这个端口不可重复。
kafka插件,通常是客户端,从kafka服务端拉取数据,此时,logstash.input无需监听端口。
ℹ️具体插件介绍查看:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
filters
filters支持多个插件类型,常用的有:
- grok 用于将非结构化事件塑造成结构化事件
- mutate 针对事件字段进行增删改
- drop 完全删除一个事件
- geoip 给事件添加地理位置
ℹ️具体插件介绍查看:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
outputs
大部分情况下,你应该始终用elasticsearch作为output输出对象。
ℹ️具体插件介绍查看:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
codecs
比较常用的插件有,json、json_lines
ℹ️具体插件介绍查看:https://www.elastic.co/guide/en/logstash/current/codec-plugins.html
三者的合作方式是:
inputs将接收事件,并将事件写入内存队列中,每一个管道的工作线程从队列里获取数据,交给filters处理,最后通过output输出。
需要注意的是,位于内存中的事件队列无法保证可靠性,因此如果不设置持久队列,则一旦出现意外,数据将丢失。
关于队列持久,有两大类,第一类是inputs将事件写入到本地磁盘存储,第二类是在logstash前放一个其它服务,例如kafka或者redis,通过其它服务来提前构建高可用的事件队列.
具体参考:https://www.elastic.co/guide/en/logstash/current/persistent-queues.html
安装
详细的安装文档参考 https://www.elastic.co/guide/en/logstash/current/installing-logstash.html#_yum
以二进制安装为例
二进制
https://mirrors.huaweicloud.com/logstash/
lsVersion=7.15.1
curl "https://mirrors.huaweicloud.com/logstash/${lsVersion}/logstash-${lsVersion}-linux-x86_64.tar.gz" -o logstash.tgz
tar xf logstash.tgz
mv logstash-${lsVersion} ../logstash && cd ..
cd logstash
docker
version: '2.3'
services:
logstash:
image: docker.elastic.co/logstash/logstash:7.15.1
container_name: logstash
volumes:
- /export/logstash/pipeline:/usr/share/logstash/pipeline
- /export/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml
- /export/logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml
- /export/logstash/data:/usr/share/logstash/data
ports:
- "5044:5044"
- "9600:9600"
networks:
- esnet
cpus: 1
mem_limit: 1g
memswap_limit: 1g
mem_reservation: 1g
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9600"]
interval: 1m30s
timeout: 10s
retries: 3
start_period: 120s
restart: on-failure
networks:
esnet:
ℹ️通过自定义的pipelines覆盖掉默认的pipelines,默认的pipelines只有一个pipeline.id:main
主配置
cp /export/logstash/config/logstash.yml /export/logstash/config/logstash.yml.default
hostName=`hostname`
cat > /export/logstash/config/logstash.yml << EOF
node.name: hadoop001
http.host: 0.0.0.0
http.port: 9600
log.level: info
config.reload.automatic: true
config.reload.interval: 10s
config.support_escapes: false
## 通过ES提供的内置用户logstash_system将logstash的状态数据发送给ES。
#xpack.monitoring.elasticsearch.username: logstash_system
#xpack.monitoring.elasticsearch.password: ${ES_PWD}
EOF
logstash 主配置写法:https://www.elastic.co/guide/en/logstash/current/logstash-settings-file.html
ℹ️logstash 通过 path.settings 来寻找目录下的 pipelines.yml 配置
✨xpack 开头的选项用于仅当ES启用了xpack和内置用户。需要提前先在ES那边创建。
步骤如下:
- 开通ES的安全配置xpack,并初始化内置用户
- 创建logstash密钥库,存放加密密码到变量中
bin/logstash-keystore create
=>输入y,表示不设置密钥库的密码
bin/logstash-keystore add ES_PWD
=>输入ES_PWD
- 删除主配置里的xpack两个选项的注释,并通过密码变量调用密码。
bin/logstash-keystore list
bin/logstash-keystore remove
管道配置
管道配置的编写一般是需要依托于beats组件,或者beats组件后的消息队列组件.
管道配置分多个步骤:input、filter、output
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
https://www.elastic.co/guide/en/logstash/current/output-plugins.html
配置文件:config/pipelines.yml
示例1
- pipeline.id: upstream_server
config.string: |
input {
kafka {
topics_pattern => "zz.it.elk\..*"
group_id => "logstash"
bootstrap_servers => "hadoop001:8123,hadoop002:8123,hadoop003:8123"
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "SCRAM-SHA-256"
sasl_jaas_config => "org.apache.kafka.common.security.scram.ScramLoginModule required username='elk' password='123456';"
codec =>"json"
}
}
output {
if [fields][log_topic] == "zz.it.elk.syslog.secure" {
pipeline { send_to => syslog }
} else {
pipeline { send_to => apache }
}
}
- pipeline.id: apache
pipeline.workers: 3
queue.type: persisted
#path.config: "/usr/share/logstash/pipeline/beats-5044.conf"
config.string: |
input {
pipeline {
address => apache
}
}
filter {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
elasticsearch {
hosts => ["hadoop001:9200","hadoop002:9200","hadoop003:9200"]
user => "index_admin"
password => "${INDEX_PWD}"
manage_template => false
index => "%{[tags][0]}-%{[tags][1]}-%{+YYYY.MM.dd}"
}
}
- pipeline.id: syslog
pipeline.workers: 1
queue.type: persisted
#path.config: "/usr/share/logstash/pipeline/beats-5045.conf"
config.string: |
input {
pipeline {
address => syslog
}
}
filter {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
elasticsearch {
hosts => ["hadoop001:9200","hadoop002:9200","hadoop003:9200"]
user => "index_admin"
password => "${INDEX_PWD}"
manage_template => false
index => "%{[tags][0]}-%{[tags][1]}-all-%{+YYYY.MM.dd}"
}
}
⚠️数据进kafka后,会转为json格式,因此需要在input中加入json编码器
示例2
- pipeline.id: k8scontainers
pipeline.workers: 3
queue.type: persisted
config.string: |
input {
kafka {
topics_pattern => "zz.it.elk.k8s.containers"
group_id => "logstash"
bootstrap_servers => "data01:8123,data02:8123,data03:8123"
security_protocol => "SASL_PLAINTEXT"
sasl_mechanism => "SCRAM-SHA-256"
sasl_jaas_config => "org.apache.kafka.common.security.scram.ScramLoginModule required username='elk' password='123456';"
codec =>"json"
}
}
filter {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
elasticsearch {
hosts => ["data01:9200","data02:9200","data03:9200"]
user => "index_admin"
password => "index_admin"
manage_template => false
index => "%{[tags][0]}-%{[kubernetes][container][name]}-%{+YYYY.MM.dd}"
}
}
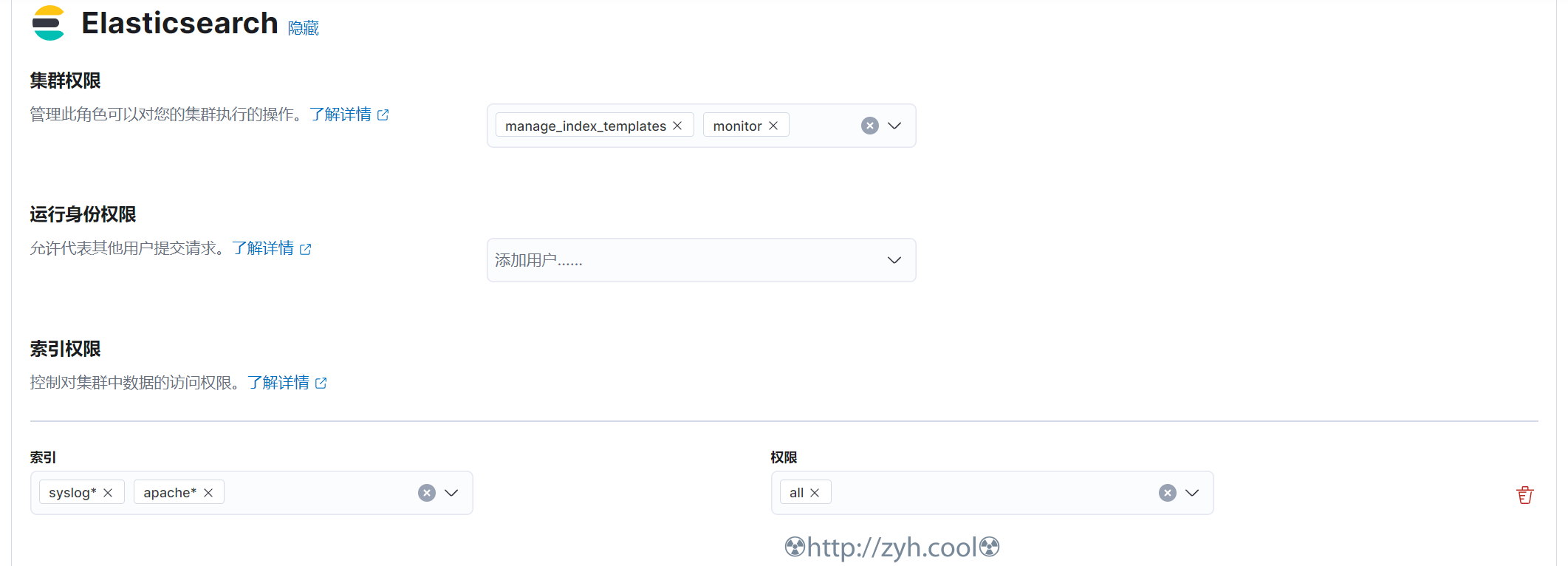
创建管道所需的ES写权限账户
⚠️output.elasticsearch.user的用户需要在ES中创建。可以使用kibana用户管理中去创建,其用户的角色权限示例如下图所示:
https://www.elastic.co/guide/en/logstash/current/ls-security.html
测试
cd /export/logstash
bin/logstash --config.test_and_exit
数据debug
pipelines.output配置stdout插件
output {
stdout {}
}
bin/logstash -e
可以观察 logstash 获取的事件
启动
cd /export/logstash
nohup bin/logstash &
配置自动重载
docker模式下的logstash已经是自动重载,如果你是二进制方式,则启动的时候追加--config.reload.automatic
当 Logstash 检测到配置文件中的更改时,它会通过停止所有输入来停止当前管道,并尝试创建使用更新配置的新管道。在验证新配置的语法后,Logstash 会验证所有输入和输出是否都可以初始化(例如,所有必需的端口都已打开)。如果检查成功,Logstash 会将现有管道与新管道交换。如果检查失败,旧管道将继续运行,并将错误传播到控制台。
在自动配置重新加载期间,JVM 不会重新启动。管道的创建和交换都发生在同一个进程中。
对filter-grok部分的更改也会重新加载,但仅在配置文件中的更改触发重新加载(或管道重新启动)时才会重新加载。
管道配置:多重管道
https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
在一个logstash实例中配置多个pipeline,甚至,还可以管道到管道
https://www.elastic.co/guide/en/logstash/current/pipeline-to-pipeline.html#pipeline-to-pipeline
管道到管道涉及一个概念:【虚拟地址】,以下面例子说明:
# config/pipelines.yml
- pipeline.id: upstream
config.string: input { stdin {} } output { pipeline { send_to => [myVirtualAddress] } }
- pipeline.id: downstream
config.string: input { pipeline { address => myVirtualAddress } }
ℹ️send_to连接虚拟地址,address创建虚拟地址
- 下游管道输入充当虚拟服务器,侦听本地进程中的单个虚拟地址。
- 只有在同一个 Logstash 上运行的上游管道输出才能将事件发送到此虚拟地址列表。
- 如果下游管道被阻塞或不可用,则上游管道输出将被阻塞。
- 当事件跨管道发送时,它们的数据被完全复制,因此对下游管道中事件的修改不会影响上游管道中的该事件。
- 管道插件可能是管道之间通信的最有效方式,但它仍然会产生性能成本。因为 Logstash 必须在 Java 堆上为每个下游管道完整复制每个事件。使用此功能可能会影响 Logstash 的堆内存利用率。
多重分销商模式
通过 beats-server.input 管道接收,在 beats-server.output 中进行事件字段判断后,通过虚拟地址分发到多个管道
缺点:分发的数据是复制的,因此内存使用会增大。
cat > /export/docker-compose-data/logstash/pipelines.yml << EOF
- pipeline.id: beats_server
config.string: |
input {
beats {
port => 5044
}
}
output {
if [tags][1] == "access" {
pipeline { send_to => access }
} else {
pipeline { send_to => error }
}
}
- pipeline.id: apache_access
pipeline.workers: 3
pipeline.batch.size: 500
queue.type: persisted
config.string: |
input {
pipeline {
address => access
}
}
filter {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
elasticsearch {
hosts => ["es01:9200"]
manage_template => false
index => "%{[tags][0]}-%{[tags][1]}-%{+YYYY.MM.dd}"
}
}
- pipeline.id: apache_error
pipeline.workers: 1
pipeline.batch.size: 125
queue.type: persisted
config.string: |
input {
pipeline {
address => error
}
}
filter {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
elasticsearch {
hosts => ["es01:9200"]
manage_template => false
index => "%{[tags][0]}-%{[tags][1]}-all-%{+YYYY.MM.dd}"
}
}
EOF
ℹ️
每一个管道的内存队列大小=pipeline.workers*pipeline.batch.size, 内存队列大小决定了同一时间可处理的事件数.
默认情况下,pipeline.workers = vcpu , pipeline.batch.size = 125.
⚠️当队列满的时候,logstash会阻塞input,防止新事件流入。
分叉路径模式
这个模式下,beats_server.input 收到数据后,beats_server.output会不经条件判断,直接将数据通过虚拟地址(es,http)复制到额外的两个管道(bufferd-es,bufferd-http)。
优点:bufferd-es 和 bufferd-http管道互不干扰,且可以分别设定过滤规则.
缺点:资源消耗方面是成倍数增加的,每多一个管道,就需要多一倍的资源.例如下列配置中,bufferd-es和bufferd-http均开启了持久化(queue.type: persisted),这意味着额外的双倍磁盘消耗。
cat > /export/docker-compose-data/logstash/pipelines.yml << EOF
- pipeline.id: beats_server
config.string: |
input {
beats {
port => 5044
}
}
output {
pipeline { send_to => [es, s3] }
}
- pipeline.id: es
pipeline.workers: 3
queue.type: persisted
config.string: |
input {
pipeline {
address => es
}
}
filter {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
elasticsearch {
hosts => ["es01:9200"]
manage_template => false
index => "%{[tags][0]}-%{[tags][1]}-%{+YYYY.MM.dd}"
}
}
- pipeline.id: s3
pipeline.workers: 1
queue.type: persisted
config.string: |
input {
pipeline {
address => s3
}
}
filter {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
s3 {}
}
EOF
⚠️根据 input 的类型,input 插件可能是 client 也可能是 server,在充当 server 角色的时候,应该保证端口唯一。
管道配置:持久队列
默认事件队列是内存级别,因此数据可能丢失,而持久队列是定期将内存数据写入到磁盘。
工作流是:输入→队列(磁盘)→过滤器+输出
当输入有事件准备好处理时,它会将事件写入队列。当写入队列成功时,输入可以向其数据源发送确认。因此,要求输入源必须支持事件确认。(并不是所有的input插件都支持,但beats和http插件是支持的).
经过过滤器和输出成功后,事件将被标记为【确认(ACKed)】.
⚠️ 如果事件在经历过滤器和输出成功后,且还未来得及标记为【确认(ACKed)】的情况下,logstash突然挂了,那么在logstash启动后,事件会被重复发送,这会导致输出端接收到重复事件。
持久队列分为两部分文件,一个是保存事件的多份数据队列文件page.<num>,一个是记录事件信息的单个检查点文件checkpoint.xxx。
- 每有x个事件被写入到队列文件,检查点文件就会更新一次。
- 每有x个事件被确认,检查点文件也会更新一次。
数据队列文件: 按照queue.page_capacity定义的大小进行切分。【最新】的一份数据文件被称之为头文件(接收input事件,只可追加),其余的叫尾文件(只读不可变),事件确认完的尾页将被删除。
检查点文件: 包含事件所在的数据文件,是否确认等信息。凡是没有被检查点记录的事件,均可以认为暂不安全.
最后,一个至关重要的点,logstash始终通过【检查点文件】来判断事件。
⚠️ logstash突然故障:
- 会导致没有记录在检查点文件里的
buffered事件丢失。(也就是还未写入磁盘的内存队列里的事件) - 会导致已经完成处理但却来不及更新进检查点文件的事件被重复输出。
pipelines.yml示例配置:
- pipeline.id: bufferd-to-disk
queue.type: persisted
queue.drain: false # 关闭logstash的时候,不等待【持久队列】的事件确认完成
queue.page_capacity: 250mb
queue.max_bytes: 1024mb # 所有【包含】未处理事件的数据队列页总大小,过大会影响性能,过小会在output压力大的时候阻塞input
queue.checkpoint.writes: 1024 # 数据队列【头页】每写入1024个事件,就刷新一次检查点文件。值越小,故障后丢失的事件就越少,磁盘io压力越大。丢失数<=值。
queue.checkpoint.acks: 1024 # 数据队列【尾页】每确认1024个事件,就刷新一次检查点文件。值越小,故障后重复发送的事件就越少,磁盘io压力越大。重复数<=值
主配置:死信队列
https://www.elastic.co/guide/en/logstash/7.15/dead-letter-queues.html
当logstash无法解析事件的时候,默认情况下logstash会丢弃或者挂起。
开启死信队列可以收集这些异常事件,确保logstash正常运行。之后,死信队列的事件需要【人工】处理。
⚠️哪怕你开启了死信队列,也要确保pipeline.output是elasticsearch,因为logstash通过elasticsearch返回的状态码来定性死信,当前判断值为400/404。
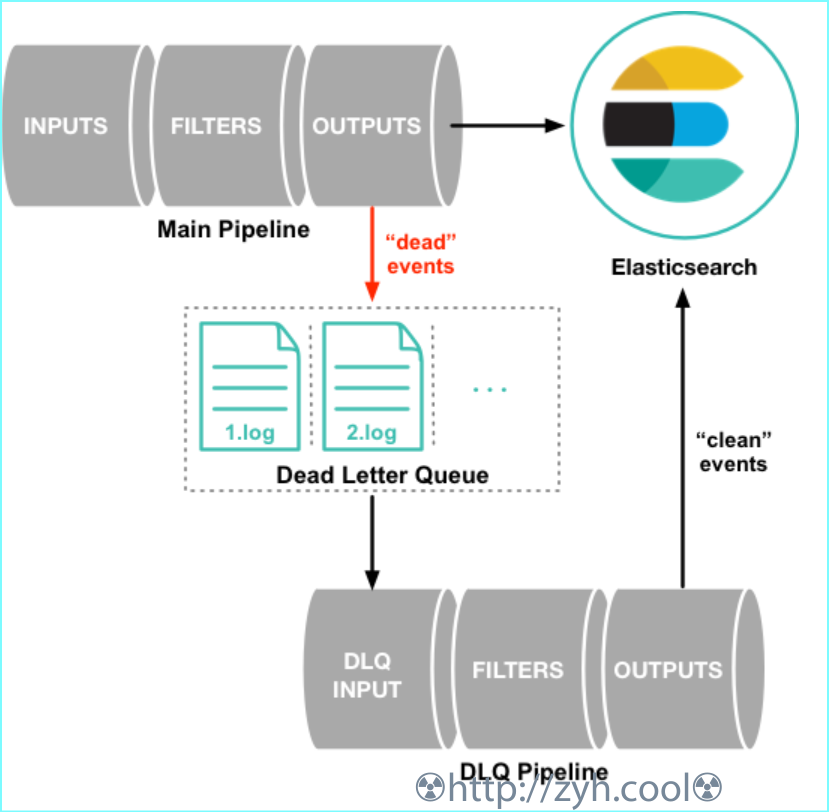
死信队列开启方式:dead_letter_queue.enable: true,它以文件形式存储,位于path.dead_letter_queue/<pipeline.id>。任意输出
⚠️两个logstash实例不能设置相同的path.dead_letter_queue
文件切分分两种方式:
- 达到了文件大小上限
dead_letter_queue.max_bytes。默认值:1024mb - 达到了刷新时间
dead_letter_queue.flush_interval。默认值: 5000ms,不能低于 1000ms
ℹ️上面几个dead_letter_queue均为主配置
人工处理死信
https://www.elastic.co/guide/en/logstash/7.15/plugins-inputs-dead_letter_queue.html
处理死信,就是新构建一个pipeline,从死信中读取异常事件,并再次处理的过程.这期间需要用到Dead_letter_queue input plugin
假设异常事件是{"geoip":{"location":"home"}} 可以看出home是不对的,不符合geoip所需要值类型.
input {
dead_letter_queue {
path => "/path/to/data/dead_letter_queue" # path.dead_letter_queue
start_timestamp => "2017-06-06T23:40:37"
commit_offsets => true
pipeline_id => "main"
}
}
filter {
mutate {
remove_field => "[geoip][location]"
}
}
output {
elasticsearch{
hosts => [ "localhost:9200" ]
}
}
commit_offsets 表示记录偏移点,意思就是input.dead_letter_queue每次不会从开头重新处理,而是从上一次的尾端开始。
start_timestamp 表示仅处理指定时间点之后进入死信队列的事件.
pipeline_id 指的是往死信队列里写异常事件的管道。默认是main
通过remove_field删除异常的字段,从而解决。
删除死信数据
关掉pipeline,然后直接物理层面删除path.dead_letter_queue/<pipeline.id>即可