前言
变量涉及到类型、值以及内存地址。
声明类型
- 基本类型:数字、字符串和布尔值
- 聚合类型:数组和结构
- 引用类型:指针、切片、映射、函数和通道
- 接口类型:接口
部分变量类型及对应的零值:
int,整型,默认是0
string,字符串,默认是空
💥字符串的表示用双引号和反引号,不可用单引号,单引号在golang里表示rune ,类似于其它语言的字节类型
字符串算是只读切片,因此无法直接修改,若真修改,先转成byte
bool,布尔,默认是false
chan,管道,默认是nil
[数组大小]数组值类型 数组,默认是nil
[]数组值类型 切片,默认是nil
map 字典,默认是nil
byte,字节,默认是0,本质上是一个整型
变量类型
如果变量值对应的是类型数据,则这类变量称之为值类型变量,也就是普通变量
如果变量值对应的是另一个变量的内存地址,则这类变量称之为引用类型变量,也叫指针变量
💁 变量的内存地址里不能存储变量自己的内存地址
值变量
方法1:
仅定义一种变量类型。
✨若变量的值没有提供,则系统会根据变量类型提供零值。
var <变量1>,<变量2> <变量类型> = <变量1的值>, <变量2的值>
package main
import "fmt"
func main(){
var a,b int = 1,2
fmt.Println(a,b)
var c,d string = "abc","def"
fmt.Println(c,d)
var e,f string = "123","456"
fmt.Println(e,f)
}
1 2
abc def
123 456
方法2:(不推荐)
可以同时定义多种类型
根据变量值,自动判断变量类型
var <变量1>, <变量2> = <变量1的值>, <变量2的值>
方法3:(函数内使用)
可以同时定义多种类型
根据变量值,自动判断变量类型
省略 var 声明关键词
- 只能用于函数体内。💥
- 仅可以用于新变量。💥
- 多个变量单行同时声明并赋值的时候,如果某一个变量是结构体字段,则同时待声明的变量都需要提前声明。
<变量1>, <变量2> := <变量1的值>,<变量2的值>
package main
import "fmt"
func main(){
n,m := "nnn", 12345
fmt.Println(n,m)
}
nnn 12345
方法4:
因式分解,常用来在函数体外声明全局变量
当然,也可以在函数体内定义局部变量
var (
<变量1> <类型1> = <变量1的值>
<变量2> <类型2> = <变量2的值>
)
方法5:
内置函数new()
pvar := new(T)
package main
import "fmt"
func main(){
var e string = "abcdef"
fmt.Println("e:"+e)
f := new(string)
f = &e
fmt.Println("f:"+*f)
}
e:abcdef
f:abcdef
✨直接返回指针
方法6:
内置函数make(T, args)
var := make(T, args)
💥仅用于切片slice、映射map、通道channel
引用变量
变量的值存储的是另一个变量的内存地址。因此,通过指针变量你可以修改另一个变量的值。
在 Go 中,有两个运算符可用于处理指针:
&运算符调用变量对象的内存地址。*运算符表示取消引用指针或声明一个指针。*指针变量取消引用指针,本质上是指针变量存储的内存地址所对应的变量对象。*变量类型声明指针。
例如:
package main
import "fmt"
func main() {
firstName := "John"
updateName(&firstName) // 3. 普通变量前加&,表示获取普通变量的内存地址
fmt.Println(firstName)
}
func updateName(name *string) { // 1. 形参变量类型前加*,表示这个形参是一个指针变量
*name = "David" // 2. 指针变量前加*,等同于指针变量所指向的普通变量
}
变量类型转换
Go 中隐式强制转换不起作用。
- 浮点和整数之间
type_name(expression)
- 字符串和数字之间
import “strconv”
strconv.Atoi(expression) 字符串到数字
package main
import (
"fmt"
"strconv"
)
func main() {
i, _ := strconv.Atoi("-42")
s := strconv.Itoa(-42)
fmt.Println(i, s)
}
普通变量和指针变量的使用区别
通过老的普通变量赋值生成的新普通变量,两者之间因为内存地址不一样,因此没有任何关联
例如:
package main
import "fmt"
func main() {
var var01 int = 123
var var02 int = var01
fmt.Printf("var01的值是:%d\nvar02的值是:%d\n", var01, var02)
fmt.Printf("var01的内存地址是:%d\nvar02的内存地址是:%d\n", &var01, &var02)
var01 = 456
fmt.Printf("var01的新值是:%d\nvar02的值不变:%d\n", var01, var02)
}
===
var01的值是:123
var02的值是:123
var01的内存地址是:824634941440
var02的内存地址是:824634941448
var01的新值是:456
var02的值不变:123
通过老的普通变量赋值生成的新指针变量,两者之间是引用关系
当普通变量被赋予新值后,对应的指针变量也可以输出新值,因为普通变量的内存地址始终没变
package main
import "fmt"
func main() {
var var01 int = 123
var var02 *int = &var01
fmt.Printf("var01的值是:%d\nvar01的内存地址是:%d\n", var01, var02)
fmt.Printf("var01的的值是(通过*var02获取):%d\n", *var02)
}
===
var01的值是:123
var01的内存地址(通过var02获取):824633802928
var01的值是(通过*var02获取):123
var01的新值是:456
var01的内存地址(通过var02获取):824633802928
var01的新值是(通过*var02获取):456
作用范围
函数内定义的变量,生命周期仅在函数被调用期间
需要注意的是:if 和 for 这些控制结构中声明的变量的作用域只在相应的代码块内。即一般情况下,局部变量的作用域可以通过代码块(用大括号括起来的部分)判断。
函数外定义的变量,可以在本级以及下一级嵌套里使用
当两种变量名一致时,函数内变量优先级更高
package main
import "fmt"
func main() {
x := 1
fmt.Println(x) //prints 1
{
fmt.Println(x) //prints 1
x := 2
fmt.Println(x) //prints 2
}
fmt.Println(x) //prints 1 (bad if you need 2)
}
数组
写法
一维数组:var <var_name> [数组大小]<type>
二维数组:var <var_name> [一维数组大小][二维数组大小]<type>
💥数组一旦定义则【长度不可变】,但你可以修改已有的元素。
🤷♂️另外,通过var声明的数组会填充默认值。
[] 填入...代表不确定数组大小由系统根据初始化的值数量自动计算大小
- […]int{99: -1} 表示初始化一个100长度的数组,末位是-1,其余是0
不管是一维数组,还是二维数组,只能存在一种类型。
最后,函数参数是数组的时候,默认是值传递。
例子
package main
import "fmt"
func main(){
array01 := [3]int{1,2,3}
array02 := [3]int{4,5,6}
array03 := [][3]int{}
array03 = append(array03, array01)
array03 = append(array03, array02)
for _,x := range(array03){
for _,y := range(x){
fmt.Println(y)
}
}
}
array03定义了一个不限行,限3列的数组,这里不限行[]的写法叫切片
切片
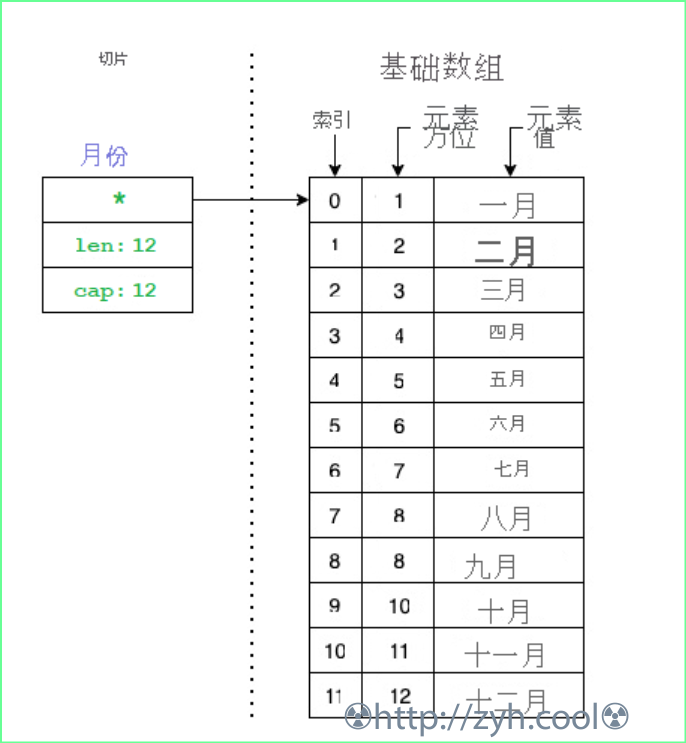
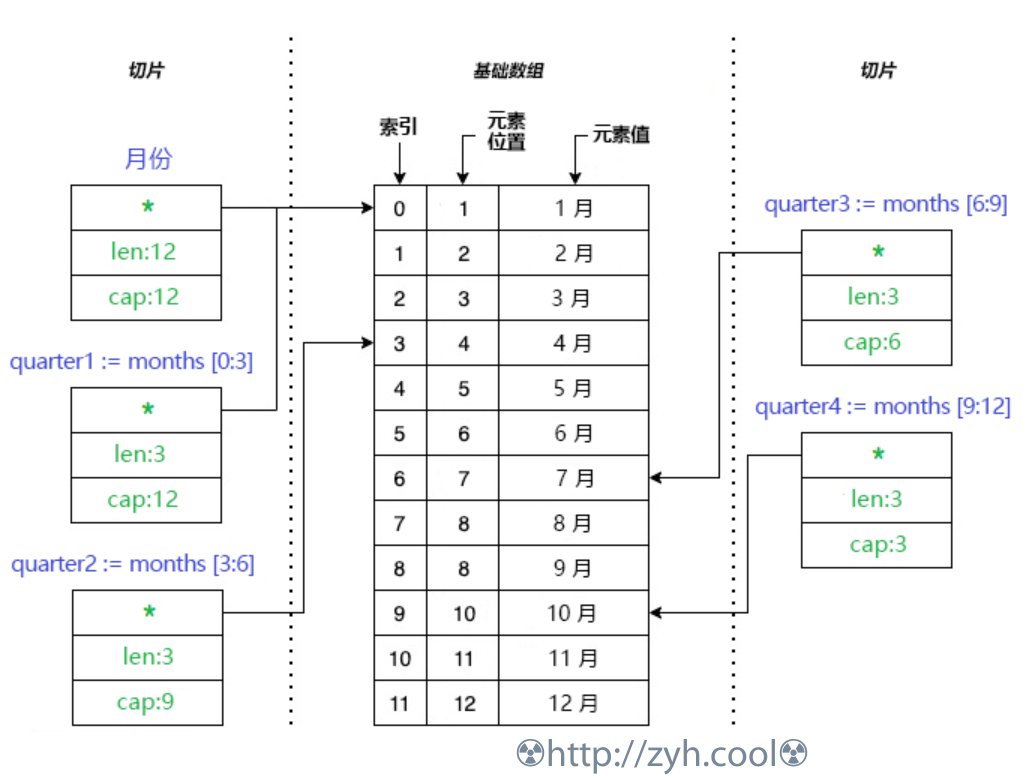
切片包含三个组件数据:
- 指向基础数组中切片可以访问的第一个元素的指针。此元素不一定是数组的第一个元素
array[0]。 - 切片的长度。切片中元素数目。
- 切片的容量。切片开头(切片可访问的第一个元素)与基础数组结束之间的元素数目。
切片是一个引用变量,因此切片变量存储的是内存地址,这个内存地址就是基础数组。
在一个基础数组上产出的切片,因基础数组不变,所以内存开销都很低。
写法
基本写法
s1 := []int{1,2,3,} // 初始化一个内置3元素,容量3的切片s1
写法2:
s1 := make([]int, <len>, <cap>)
// <len>是定义切片内元素的长度,<cap>是定义切片容纳元素的上限数
长度决定了切片的初始元素个数,容量决定了切片底层数组的元素个数
常用函数
这两个函数是仅可以用于切片的,不可用于数组的。
- 追加元素到切片
新切片 := append(<目标切片>, <填充元素>),用来扩展目标切片并切出一个新切片。新切片是否在<目标切片>基础上操作取决于<目标切片>容量是否充足。
<填充元素> 如果是一个切片,则需要在其后面追加...。
就如同新切片 := append(<目标切片>, <填充切片>...)
- 完全复制一个切片
copy(<目标切片>, <需复制切片>),用来将切片复制到目标切片,目标切片有多长,就填充多长。【目标切片是全新的,它的基础数组也是全新的】
- 从切片里删除元素
切片里没有内置删除功能.
package main
import "fmt"
func main() {
letters := []string{"A", "B", "C", "D", "E"}
remove := 2
if remove < len(letters) {
fmt.Println("Before", letters, "Remove ", letters[remove])
letters = append(letters[:remove], letters[remove+1:]...)
fmt.Println("After", letters)
}
}
切片截取
s[:3] //忽略首位数字写法:截取0-2构建新切片
s[3:] //忽略末尾数字写法:截取3-最后,构建新切片
遍历输出
用range关键字
如果是数组或者切片,它返回(元素序号,元素值)
如果是集合,它返回(key, value)
for _, i := range <切片>{
fmt.Println(i)
}
映射
map 类似于 pythhon 的字典,由kv对组成,它是无序的,因此,在使用 range 返回的时候,无法决定返回顺序。
写法
// 通过 var 声明一个map,会自动附加默认值。
var m1 map[<key_type>]value_type
// 声明的时候
m1 := map[<key_type>]value_type {
"key_type":"value_type"
}
😒nil map不可通过m1[key]=value加集合元素。
所以,如果单纯的声明一个空映射(就是什么都没有,nil都没有),可以使用make()
package main
import "fmt"
func main() {
m := make(map[string]int)
m["a"]=1
fmt.Println(m["a"])
}
例子:
m1 := map[string]int{"河南":1, "郑州":2}
fmt.Println(m1["河南"])
fmt.Println(m1["郑州"])
===
1
2
删除
delete(
技巧
下面这个例子,通过判断map取值返回的第二个值ok,来判断接下来的逻辑行为。
package main
import "fmt"
func main() {
x := map[string]string{"one":"a","two":"","three":"c"}
if _,ok := x["two"]; !ok {
fmt.Println("no entry")
}
}