通过 prometheus-operator
部署文档
https://prometheus-operator.dev/docs/prologue/quick-start/
如果采用的是kubeadm安装的k8s,或许会用到
https://prometheus-operator.dev/docs/kube-prometheus-on-kubeadm/#kubeadm-pre-requisites
提到的信息。
架构图
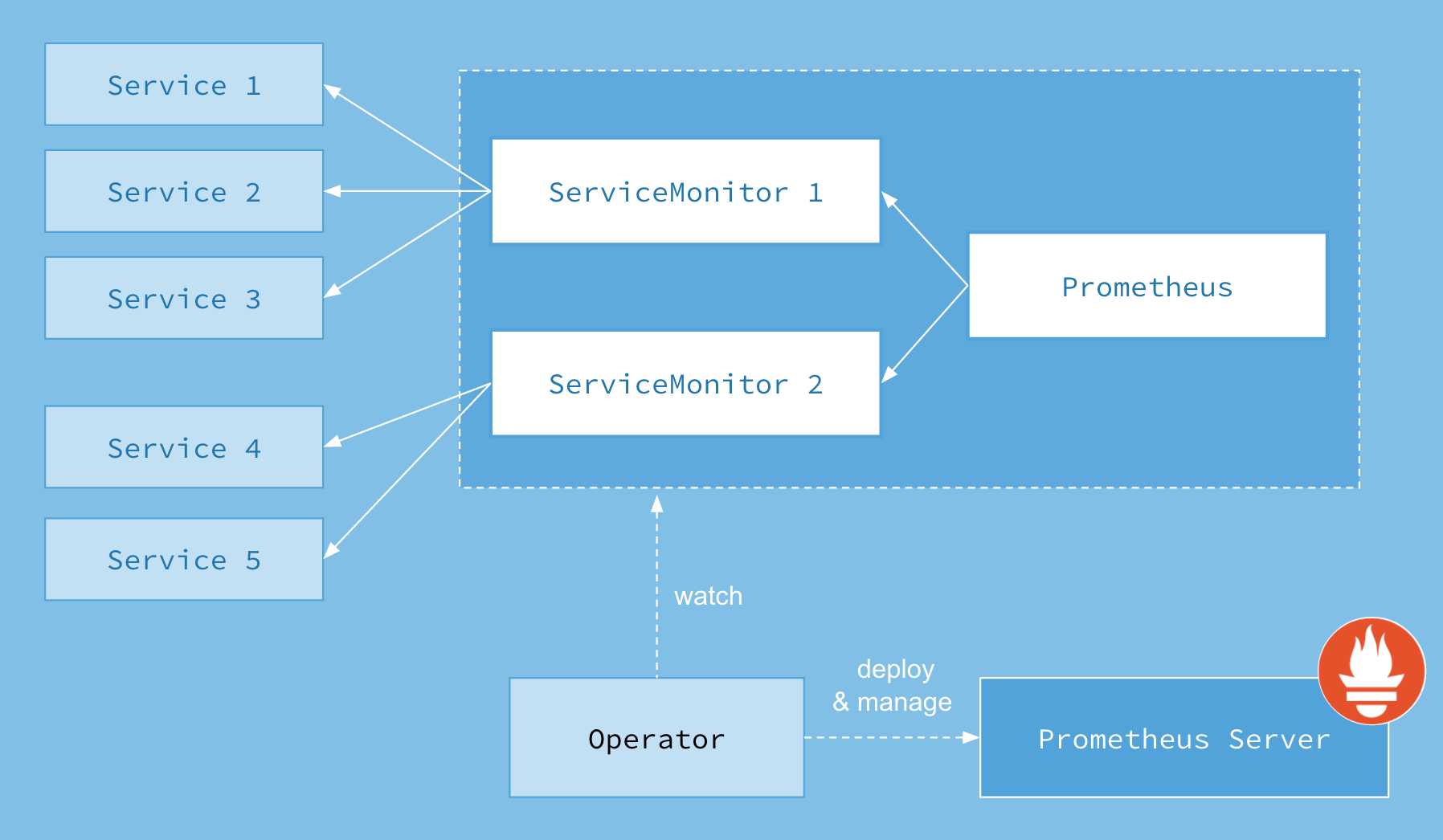
这里的 servicemonitor 资源对象很关键
监控的东西
- cluster state via kube-state-metrics
- nodes via the node_exporter
- kubelets
- apiserver
- kube-scheduler
- kube-controller-manager
基本步骤
拉取代码
git clone https://github.com/prometheus-operator/kube-prometheus.git
部署到k8s
ℹ️资源会部署在monitoring命名空间中
kubectl create -f manifests/setup
# 等待上述命令资源跑完
kubectl create -f manifests/
# 等待所有 pod 创建完毕
kubectl get pod -n monitoring
添加ingress配置
ℹ️需先部署完 ingress,例如
kubectl get svc -n ingress-nginx
===
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.210.139 10.200.16.11 80:32489/TCP,443:30936/TCP 88m
ingress-nginx-controller-admission ClusterIP 10.96.128.101 <none> 443/TCP 88m
上述 ingress-nginx-controller 已经分到了 EXTERNAL-IP:10.200.16.11
部署下面的 ingress 配置
kind: Ingress
apiVersion: networking.k8s.io/v1
metadata:
name: prometheus-ingress
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: grafana.it.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
- host: proms.it.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
- host: alert.it.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
解析 grafana.it.local 和 proms.it.local 到 svc 对象 ingress-nginx-controller 关联的 EXTERNAL-IP.
最后通过 http://grafana.it.local 和 http://proms.it.local 访问
其中 grafana 的默认账户密码都是 admin,效果如图:
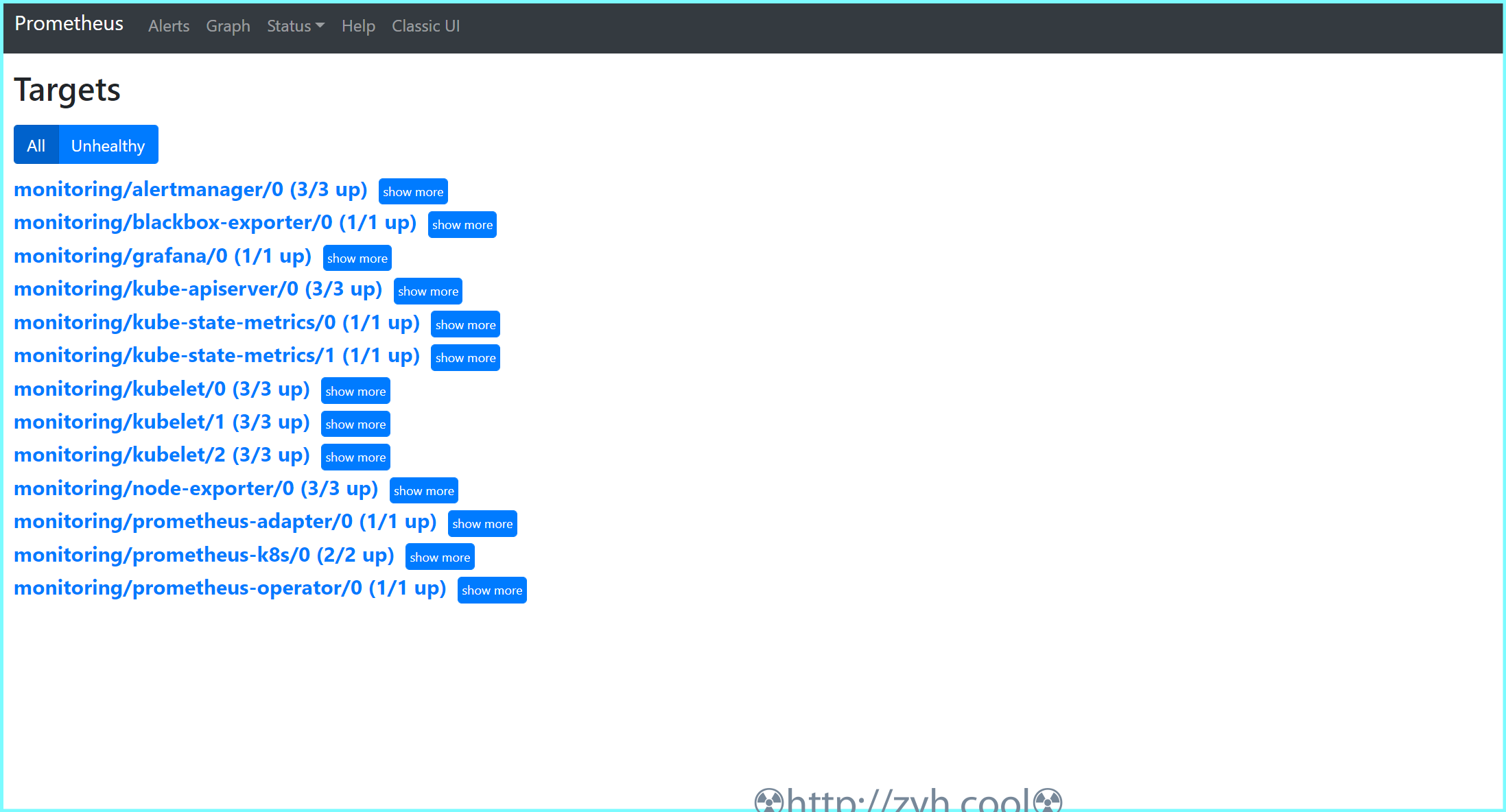
其中 prometheus 的效果如图:
添加告警
配置相关可以在 kube-prometheus/manifests/alertmanager-secret.yaml 中找到
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.21.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
global:
resolve_timeout: 5m
http_config: {}
smtp_hello: localhost
smtp_require_tls: true
pagerduty_url: https://events.pagerduty.com/v2/enqueue
opsgenie_api_url: https://api.opsgenie.com/
wechat_api_url: https://qyapi.weixin.qq.com/cgi-bin/
victorops_api_url: https://alert.victorops.com/integrations/generic/20131114/alert/
route:
receiver: Default
group_by:
- namespace
routes:
- receiver: Watchdog
match:
alertname: Watchdog
- receiver: Critical
match:
severity: critical
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
inhibit_rules:
- source_match:
severity: critical
target_match_re:
severity: warning|info
equal:
- namespace
- alertname
- source_match:
severity: warning
target_match_re:
severity: info
equal:
- namespace
- alertname
receivers:
- name: Default
webhook_configs:
- url: "..."
- name: Critical
webhook_configs:
- url: "..."
- name: Watchdog
templates: []
type: Opaque
如上命令所示,添加 receivers ,这里均采用 webhook 方式
部署新配置,并reload alertmanager
kubectl apply -f alertmanager-secret.yaml
curl -X POST http://<alertmanager_addr>/-/reload
修改默认的prometheus规则
默认的规则位于 prometheusrule 资源对象中
kubectl get prometheusrule -n monitoring
NAME AGE
alertmanager-main-rules 6d22h
kube-prometheus-rules 6d22h
kube-state-metrics-rules 6d22h
kubernetes-monitoring-rules 6d22h
node-exporter-rules 6d22h
prometheus-k8s-prometheus-rules 6d22h
prometheus-operator-rules 6d22h
通过 kubectl edit 修改即可
可能出现的问题
kube-controller-manager和kube-scheduler状态为down
prometheus页面中可能会看到有一些错误,两个核心组件kube-controller-manager和kube-scheduler是down

其原因在于,prometheus-operator的ServiceMonitor资源对象指定的svc不存在
[root@k8s01 my-yaml]# kubectl get servicemonitor -n monitoring
NAME AGE
alertmanager 2d19h
blackbox-exporter 2d19h
coredns 2d19h
grafana 2d19h
kube-apiserver 2d19h
kube-controller-manager 2d19h
kube-scheduler 2d19h
kube-state-metrics 2d19h
kubelet 2d19h
node-exporter 2d19h
prometheus-adapter 2d19h
prometheus-k8s 2d19h
prometheus-operator 2d19h
以kube-scheduler为例
[root@k8s01 my-yaml]# kubectl get servicemonitor kube-scheduler -n monitoring -o yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
......
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-scheduler
可以看到 kube-scheduler 的 servicemonitor 指向拥有 app.kubernetes.io/name: kube-scheduler 和 ports.name: https-metrics 的 svc
建立servicemonitor所需的svc
查看服务pod的标签
[root@k8s01 my-yaml]# kubectl get pod -n kube-system | grep kube-scheduler
kube-scheduler-k8s01 1/1 Running 0 36m
kube-scheduler-k8s02 1/1 Running 0 18m
kube-scheduler-k8s03 1/1 Running 0 16m
[root@k8s01 my-yaml]# kubectl get pod kube-scheduler-k8s01 -n kube-system -o yaml | grep -A 2 labels
labels:
component: kube-scheduler
tier: control-plane
--
f:labels:
.: {}
f:component: {}
如上可以看到,在kubeadm安装的k8s中,kube-scheduler的 labels 是 component: kube-scheduler。
最后生成svc配置
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler-prometheus
labels:
app.kubernetes.io/name: kube-scheduler # 关键
spec:
selector:
component: kube-scheduler # 关键
ports:
- name: https-metrics # 关键
port: 10259 # 关键
targetPort: 10259 # 关键
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager-prometheus
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
修改服务监听地址
默认kubeadm安装的kube-controller-manager和kube-scheduler监听地址都是127.0.0.1,这导致无法被采集,因此需要改成0.0.0.0。
修改 static pod 配置即可。
sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-controller-manager.yaml
sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-scheduler.yaml
修改完,k8s会自动重建相应的pod。
通过 prometheus 配置清单
主配置简写
# prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
存储
本地卷
# prometheus-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-local
labels:
app: prometheus
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
storageClassName: local-storage
local:
path: /data/k8s/prometheus # 数据存储路径需要提前在k8s节点上创建
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1 # 利用节点亲和性存放在 node1 节点上
persistentVolumeReclaimPolicy: Retain # PVC 删除的时候,PV保留
---
# prometheus-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data
namespace: monitor
spec:
selector:
matchLabels:
app: prometheus # 绑定到 app: prometheus 的 pv 上
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: local-storage
prometheus所需的授权服务账户
# prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
主程序
# prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
initContainers: # 初始化 prometheus 的存储路径权限
- name: fix-permissions
image: busybox
command: [chown, -R, "nobody:nobody", /prometheus]
volumeMounts:
- name: data
mountPath: /prometheus
containers:
- image: prom/prometheus:v2.34.0
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus" # 指定tsdb数据路径
- "--storage.tsdb.retention.time=24h"
- "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" # 支持热更新,直接执行 curl -X POST localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
name: http
volumeMounts:
- name: config-volume
mountPath: "/etc/prometheus"
- name: data
mountPath: "/prometheus"
resources:
requests:
cpu: 100m
memory: 512Mi
limits: # 根据抓取情况调整资源上限。
cpu: 100m
memory: 512Mi
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data
- name: config-volume
configMap:
name: prometheus-config
暴漏服务
# prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http
通过查询nodeport端口来访问
➜ kubectl get svc -n monitor
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.96.194.29 <none> 9090:30980/TCP 13h
通过 http://任意节点IP:30980 访问 prometheus 的 webui 服务了