前言
kubernetes/cluster/addons/fluentd-elasticsearch at master · kubernetes/kubernetes (github.com)
EFK包含三个组件:
- fluentd 采集器。采集日志
- elasticsearch 搜索引擎。处理日志
- kibana 展示。展示日志
数据过程:
Pod日志 ☞ fluentd ☞ Elasticsearch ☞ Kibana
👙如果pod的日志是stdout和stderr,则日志的生命周期和pod的生命周期是一致的。fluentd无法采集到已经删除的pod的日志。
更加复杂和优化的数据流:
Fluentd+Kafka+Logstash+Elasticsearch+Kibana
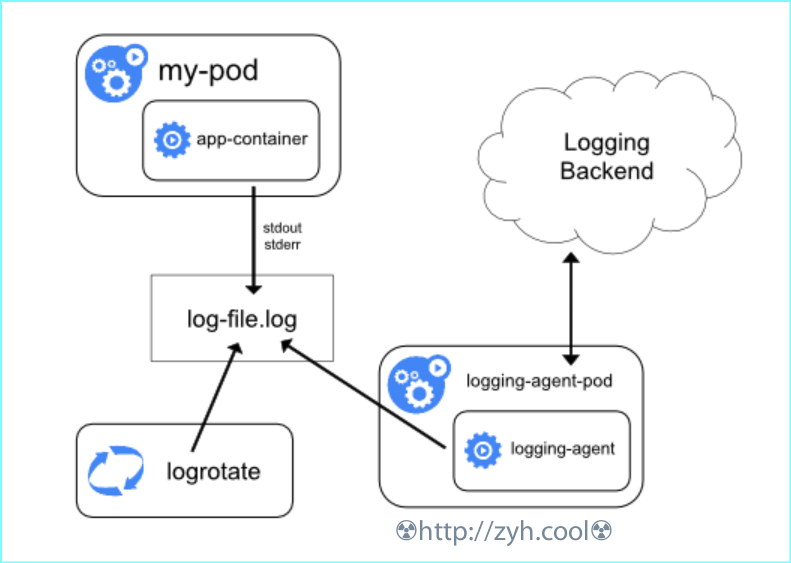
结构
集群模式,节点级收集器收集日志。
其结构图如下:
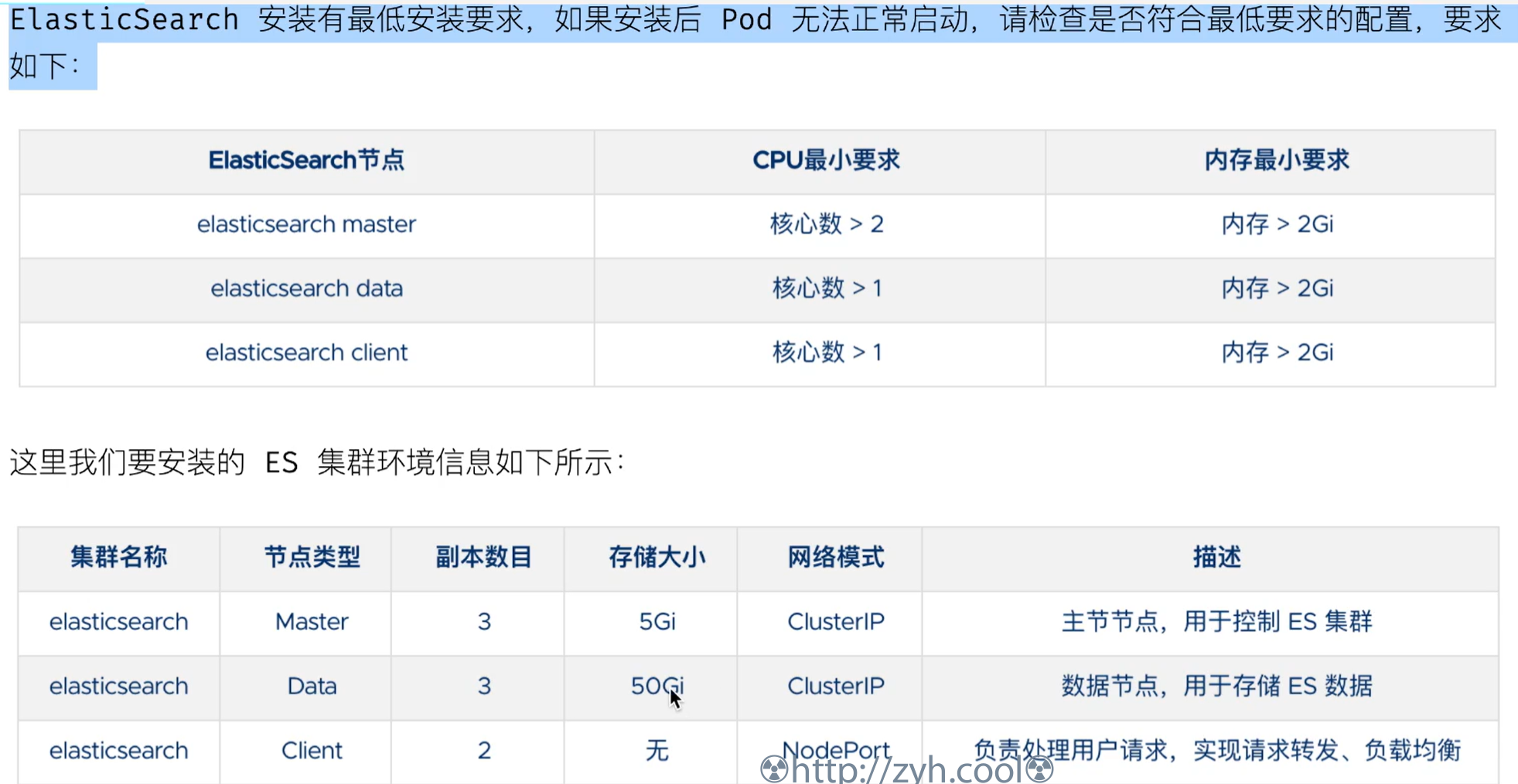
ES集群要求
安装步骤
我们通过 helm 包管理器进行安装。其地址为:Artifact Hub
⚠️需要注意的是,elasticsearch和kibana版本要保持一致
elasticsearch
部署
证书和授权密码
ES 7以上默认启用X-PACK,而X-PACK的启用,需要证书授权
- 生成证书文件
docker run --name elastic-certs -i -w /app elasticsearch:7.12.0 /bin/sh -c "elasticsearch-certutil ca --out /app/elastic-stack-ca.p12 --pass '' \
&& elasticsearch-certutil cert --name security-master --dns security-master --ca /app/elastic-stack-ca.p12 --ca-pass '' --pass '' --out /app/elastic-certificates.p12"
docker cp elastic-certs:/app/elastic-certificates.p12 . && docker rm -f elastic-certs
openssl pkcs12 -nodes -passin pass:'' -in elastic-certificates.p12 -out elastic-certificate.pem
- 创建证书对象和集群密码
kubectl create secret -n logging generic elastic-certs --from-file=elastic-certificates.p12
kubectl create secret -n logging generic elastic-auth --from-literal=username=elastic --from-literal=password=ydzsio321
安装ES集群
https://artifacthub.io/packages/helm/elastic/elasticsearch
添加repo到本地,下载chart包到本地,并解压
helm repo add elastic https://helm.elastic.co
helm repo update
helm fetch elastic/elasticsearch --version 7.12.0
tar xf elasticsearch*.tgz && cd elasticsearch
这里安装ES的三个角色,分别是:
- master 负责集群间的管理工作
- data 负责存储数据
- client 负责代理 ElasticSearch Cluster 集群,负载均衡
自定义配置:https://artifacthub.io/packages/helm/elastic/elasticsearch#configuration
👙需要先配置 storageclass,假设这里的 storageclass 是 nfs-storage
- master 节点配置
在 Chart 目录下面创建用于 Master 节点安装配置的 values 文件
# values-master.yaml
## 设置集群名称
clusterName: "elasticsearch"
## 设置节点名称
nodeGroup: "master"
## 设置角色
roles:
master: "true"
ingest: "false"
data: "false"
# ============镜像配置============
## 指定镜像与镜像版本
image: "elasticsearch"
imageTag: "7.12.0"
## 副本数
replicas: 3
# ============资源配置============
## JVM 配置参数
esJavaOpts: "-Xmx1g -Xms1g"
## 部署资源配置(生成环境一定要设置大些)
resources:
requests:
cpu: "2000m"
memory: "2Gi"
limits:
cpu: "2000m"
memory: "2Gi"
## 数据持久卷配置
persistence:
enabled: true
## 存储数据大小配置
volumeClaimTemplate:
storageClassName: nfs-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============调度配置============
## 设置调度策略
## - hard:只有当有足够的节点时 Pod 才会被调度,并且它们永远不会出现在同一个节点上
## - soft:尽最大努力调度
antiAffinity: "soft"
tolerations:
- operator: "Exists" ##容忍全部污点
- data 节点配置
# values-data.yaml
# ============设置集群名称============
## 设置集群名称
clusterName: "elasticsearch"
## 设置节点名称
nodeGroup: "data"
## 设置角色
roles:
master: "false"
ingest: "true"
data: "true"
# ============镜像配置============
## 指定镜像与镜像版本
image: "elasticsearch"
imageTag: "7.12.0"
## 副本数(建议设置为3,我这里资源不足只用了1个副本)
replicas: 1
# ============资源配置============
## JVM 配置参数
esJavaOpts: "-Xmx1g -Xms1g"
## 部署资源配置(生成环境一定要设置大些)
resources:
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
## 数据持久卷配置
persistence:
enabled: true
## 存储数据大小配置
volumeClaimTemplate:
storageClassName: nfs-storage
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============调度配置============
## 设置调度策略
## - hard:只有当有足够的节点时 Pod 才会被调度,并且它们永远不会出现在同一个节点上
## - soft:尽最大努力调度
antiAffinity: "soft"
## 容忍配置
tolerations:
- operator: "Exists" ##容忍全部污点
- client 节点配置
# values-client.yaml
# ============设置集群名称============
## 设置集群名称
clusterName: "elasticsearch"
## 设置节点名称
nodeGroup: "client"
## 设置角色
roles:
master: "false"
ingest: "false"
data: "false"
# ============镜像配置============
## 指定镜像与镜像版本
image: "elasticsearch"
imageTag: "7.12.0"
## 副本数
replicas: 1
# ============资源配置============
## JVM 配置参数
esJavaOpts: "-Xmx1g -Xms1g"
## 部署资源配置(生成环境一定要设置大些)
resources:
requests:
cpu: "1000m"
memory: "2Gi"
limits:
cpu: "1000m"
memory: "2Gi"
## 数据持久卷配置
persistence:
enabled: false
# ============安全配置============
## 设置协议,可配置为 http、https
protocol: http
## 证书挂载配置,这里我们挂入上面创建的证书
secretMounts:
- name: elastic-certs
secretName: elastic-certs
path: /usr/share/elasticsearch/config/certs
## 允许您在/usr/share/elasticsearch/config/中添加任何自定义配置文件,例如 elasticsearch.yml
## ElasticSearch 7.x 默认安装了 x-pack 插件,部分功能免费,这里我们配置下
## 下面注掉的部分为配置 https 证书,配置此部分还需要配置 helm 参数 protocol 值改为 https
esConfig:
elasticsearch.yml: |
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.enabled: true
# xpack.security.http.ssl.truststore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
# xpack.security.http.ssl.keystore.path: /usr/share/elasticsearch/config/certs/elastic-certificates.p12
## 环境变量配置,这里引入上面设置的用户名、密码 secret 文件
extraEnvs:
- name: ELASTIC_USERNAME
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: ELASTIC_PASSWORD
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
# ============Service 配置============
service:
type: NodePort
nodePort: "30200"
- 添加污点容忍,允许调度到master节点上。
正常情况下,你不应该让其调度到master节点上。
tolerations:
- key: "role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
- 开始安装
kubectl create ns logging
helm upgrade --install es-master -f values-master.yaml --namespace logging .
helm upgrade --install es-data -f values-data.yaml --namespace logging .
helm upgrade --install es-client -f values-client.yaml --namespace logging .
- 校验
kubectl run cirros-$RANDOM -it --rm --restart=Never --image=cirros -- curl --user elastic:ydzsio321 -H 'Content-Type: application/x-ndjson' http://10.96.105.164:9200/
{
"name" : "elasticsearch-master-2",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "pihlND64SqKGge_RneVeFg",
"version" : {
"number" : "7.12.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "78722783c38caa25a70982b5b042074cde5d3b3a",
"build_date" : "2021-03-18T06:17:15.410153305Z",
"build_snapshot" : false,
"lucene_version" : "8.8.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
可能出现的问题
# kubectl describe pod elasticsearch-master-0 -n logging
Q: pod has unbound immediate PersistentVolumeClaims
A: 检查 pvc 状态。
Q: Insufficient cpu
A: cpu 资源不足,无法调度, 调低 cpu 资源的 request。
👙statefulset 资源在更新的时候,是倒叙更新,例如这里有三个es-master,则先更新 elasticsearch-master-2,所以在修正配置之后,应该优先观察 elasticsearch-master-2 的状态。
kibana
部署
下载chart包到本地,并解压
helm pull elastic/kibana --untar --version 7.12.0
cd kibana
修改 values.yaml
---
elasticsearchHosts: "http://elasticsearch-client:9200"
replicas: 1
extraEnvs:
- name: "ELASTICSEARCH_USERNAME"
valueFrom:
secretKeyRef:
name: elastic-auth
key: username
- name: "ELASTICSEARCH_PASSWORD"
valueFrom:
secretKeyRef:
name: elastic-auth
key: password
image: "docker.elastic.co/kibana/kibana"
imageTag: "7.12.0"
imagePullPolicy: "IfNotPresent"
resources:
requests:
cpu: "256m"
memory: "1Gi"
limits:
cpu: "500m"
memory: "1Gi"
protocol: http
serverHost: "0.0.0.0"
healthCheckPath: "/app/kibana"
podSecurityContext:
fsGroup: 1000
securityContext:
capabilities:
drop:
- ALL
# readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
httpPort: 5601
updateStrategy:
type: "Recreate"
kibanaConfig:
kibana.yml: |
i18n.locale: "zh-CN"
service:
type: NodePort
port: 5601
nodePort: "30601"
httpPortName: http
ingress:
enabled: false
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 3
timeoutSeconds: 5
👙也可以将 svc 改为 LB 模式。
service:
type: LoadBalancer
loadBalancerIP: ""
port: 5601
nodePort: ""
labels: {}
annotations:
{}
# cloud.google.com/load-balancer-type: "Internal"
# service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0
#service.beta.kubernetes.io/azure-load-balancer-internal: "true"
# service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
# service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true"
根据你的环境修改,我这里环境用了metallb组件,用来模拟LB,所以annotations不需要添加任何注释
启动
helm upgrade --install kibana -f values.yaml --namespace logging .
kibana webui配置
访问:http://10.200.16.101:30601/
添加模式分区
路径:Stack Management->Index patterns
Index pattern name: logstash*
Time field: @timestamp
fluentd
官方文档:docs.fluentd.org
👙td-agent 软件是一个官方RPM发行版
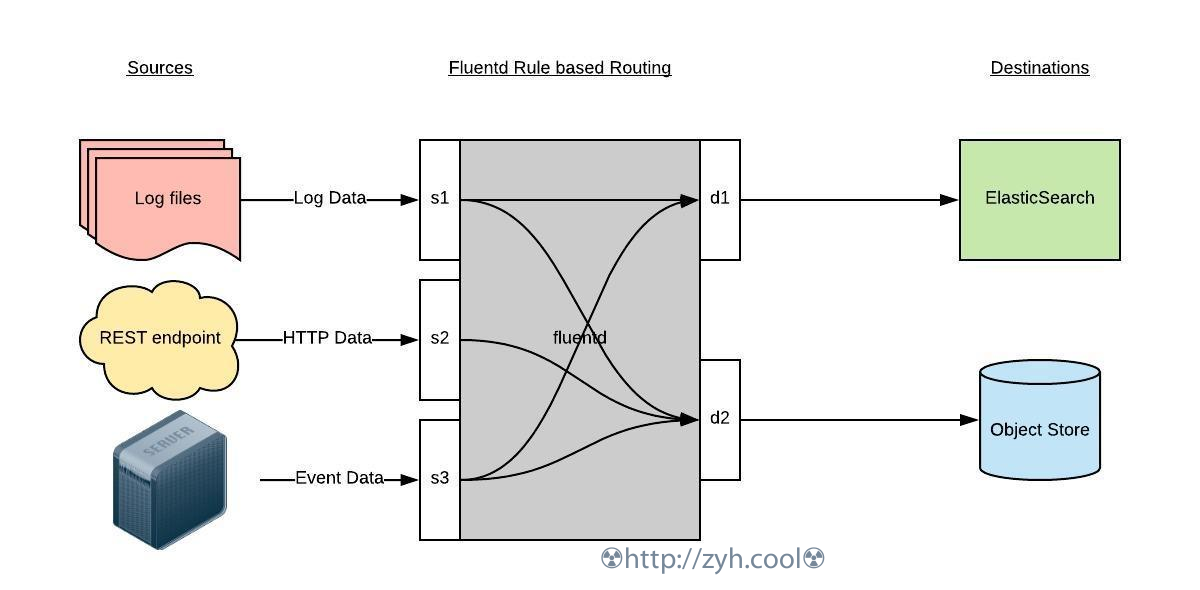
fluentd 主要运行步骤如下:
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务去
日志源配置¶
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
<source>
@id fluentd-containers.log # 日志源ID
@type tail # Fluentd 内置的输入方式,通过 tail 插件不停地从源文件中获取新的日志。
path /var/log/containers/*.log # 挂载的服务器Docker容器日志地址
pos_file /var/log/es-containers.log.pos # position 位置文件,记录fluent的读取位置
tag raw.kubernetes.* # 设置日志标签, 在 fluent 的 filter 过滤配置中根据标签过滤日志
read_from_head true # 从日志文件开头读取
<parse> # 多行格式化成JSON
@type multi_format # 使用 multi-format-parser 解析器插件
<pattern> # 匹配配置段
format json # JSON 解析器
time_key time # 指定事件时间的时间字段
time_format %Y-%m-%dT%H:%M:%S.%NZ # 时间格式
</pattern>
<pattern> # 多行日志匹配模式
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
上面配置部分参数说明如下:
- id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
- type:Fluentd 内置的指令,
tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据。 - path:
tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。 - pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
- tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置¶
上面是日志源的配置,接下来看看如何将日志数据发送到 Elasticsearch:
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
type_name fluentd
host "#{ENV['OUTPUT_HOST']}"
port "#{ENV['OUTPUT_PORT']}"
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"
queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"
overflow_action block
</buffer>
</match>
- match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成
**。 - id:目标的一个唯一标识符。
- type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
- log_level:指定要捕获的日志级别,我们这里配置成
info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。 - host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
- logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为
true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。 - Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
过滤¶
由于 Kubernetes 集群中应用太多,也还有很多历史数据,所以我们可以只将某些应用的日志进行收集,比如我们只采集具有 logging=true 这个 Label 标签的 Pod 日志,这个时候就需要使用 filter,如下所示:
# 删除无用的属性,将 remove_keys 指定的 key 从包含 raw.kubernetes.* 标签的日志中移除。
<filter raw.kubernetes.**>
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有logging=true标签的Pod日志
<filter raw.kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
部署
👙fluentd 输出到 es,需要 es 插件,因此应该选用包含 es 插件的 fluentd 镜像。
下载chart包到本地,并解压
helm repo add kokuwa https://kokuwaio.github.io/helm-charts
helm search repo kokuwa/fluentd-elasticsearch -l
helm pull --untar kokuwa/fluentd-elasticsearch --version 11.14.0
cd fluentd-elasticsearch
- 编辑 values.yaml
- 挂载日志文件到容器
hostLogDir:
varLog: /var/log
#dockerContainers: /var/lib/docker/containers
#dockerContainers: /export/docker-data-root/containers
#dockerContainers: /var/log/containers
libSystemdDir: /usr/lib64
👙 默认 fluentd 会在容器里访问 /var/log/containers/*.log ,但这个目录下其实是软连接,指向了 /var/log/pods/。
通过 varLog: /var/log 挂载后:
如果 cri 是 docker,则 /var/log/pods 会进一步软连接到 /var/lib/docker/containers 下,因为 /var/lib/docker/containers 并不在 /var/log 下。因此,需要额外挂载 dockerContainers: /var/lib/docker/containers 到容器里。
如果 cri 是 containerd,则 /var/log/pods 会直接写入实际文件。因此,这时候 dockerContainers: 无需挂载。但考虑到 helm charts 目前模板没有适配 containerd,因此依然填入 dockerContainers: /var/log/pods
- 修改 flentd 的输出配置,这里是 elasticsearch
👙这里的配置,会在ES里创建 k8s-%Y.%M.%d 的索引,并存储所有收集的日志。
elasticsearch:
auth:
enabled: true
user: elastic
password: null
existingSecret:
name: elastic-auth
key: password
includeTagKey: true
setOutputHostEnvVar: true
# If setOutputHostEnvVar is false this value is ignored
hosts: ["elasticsearch-client:9200"]
indexName: "fluentd"
# 索引前缀
logstash:
enabled: true
prefix: "k8s"
prefixSeparator: "-"
dateformat: "%Y.%m.%d"
# 自动创建生命周期策略, 默认是关闭
ilm:
enabled: false
policy_id: logstash-policy
policy: {}
# example for ilm policy config
# phases:
# hot:
# min_age: 0ms
# actions:
# rollover:
# max_age: 30d
# max_size: 20gb
# set_priority:
# priority: 100
# delete:
# min_age: 60d
# actions:
# delete:
policies: {}
# example for ilm policies config
# ilm_policy_id1: {}
# ilm_policy_id2: {}
policy_overwrite: false
# 自动创建索引模板, 默认是关闭
template:
enabled: false
overwrite: false
useLegacy: true
name: fluentd-template
file: fluentd-template.json
content: |-
{
"index_patterns": [
"k8s-*"
],
"settings": {
"index": {
"number_of_replicas": "3"
}
}
}
添加master节点的容忍,允许 fluentd 部署到 master 节点上
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
添加节点选择器,仅部署到需要搜集日志的节点上
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
👙如果节点需要收集日志,则给节点打标签
kubectl label nodes <node_name> beta.kubernetes.io/fluentd-ds-ready=true
开始安装,或者更新
helm upgrade --install fluentd --namespace logging -f values.yaml .
测试
👙默认情况下,这个 helm chart 的 template/configmap.yaml 里并没有过滤日志,可以在 configmap.yaml 中 containers.input.conf: |- 部分的最后加入下面的配置,从而通过给容器添加标签来决定是否收集容器日志。
这里的两段,分别是删除日志事件里的无用标签和只保留包含 logging="true" 标签的pod日志。
# 删除一些多余的属性
<filter kubernetes.**>
@type record_transformer
remove_keys $.docker.container_id,$.kubernetes.container_image_id,$.kubernetes.pod_id,$.kubernetes.namespace_id,$.kubernetes.master_url,$.kubernetes.labels.pod-template-hash
</filter>
# 只保留具有logging=true标签的Pod日志
<filter kubernetes.**>
@id filter_log
@type grep
<regexp>
key $.kubernetes.labels.logging
pattern ^true$
</regexp>
</filter>
# 忽略 default 命名空间下的日志
# 这里的 kubernetes.var.log.containers.*_default_* 依然是匹配日志事件中的 tag 字段标签
<match kubernetes.var.log.containers.*_default_*>
@type null
</match>
测试pod demo
👙这个demo会自动输出时间到 stdout
2022-05-01T11:17:25.355158001+08:00 stdout F 131: Sun May 1 03:17:25 UTC 2022
2022-05-01T11:17:26.355906645+08:00 stdout F 132: Sun May 1 03:17:26 UTC 2022
2022-05-01T11:17:27.356902598+08:00 stdout F 133: Sun May 1 03:17:27 UTC 2022
2022-05-01T11:17:28.357654227+08:00 stdout F 134: Sun May 1 03:17:28 UTC 2022
2022-05-01T11:17:29.35856036+08:00 stdout F 135: Sun May 1 03:17:29 UTC 2022
2022-05-01T11:17:30.359381367+08:00 stdout F 136: Sun May 1 03:17:30 UTC 2022
apiVersion: v1
kind: Pod
metadata:
name: counter
labels:
logging: "true" # 一定要具有该标签才会被采集
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]
校验 elasticsearch
确认 elasticsearch 是否接收到来自 fluentd 发送的数据
kubectl run cirros-$RANDOM -it --rm --restart=Never --image=cirros -- curl --user elastic:ydzsio321 -H 'Content-Type: application/x-ndjson' http://10.96.105.164:9200/_cat/indices | grep k8s
===
yellow open k8s-2022.05.01 APoJ5ABzRn67xl72_x4zdQ 1 1 86 0 178.1kb 178.1kb
问题
Q: fluentd 不停重启,Elasticsearch buffers found stuck longer than 300 seconds.
A:
其他 kibana 配置
配置一个展示k8s error错误的图标
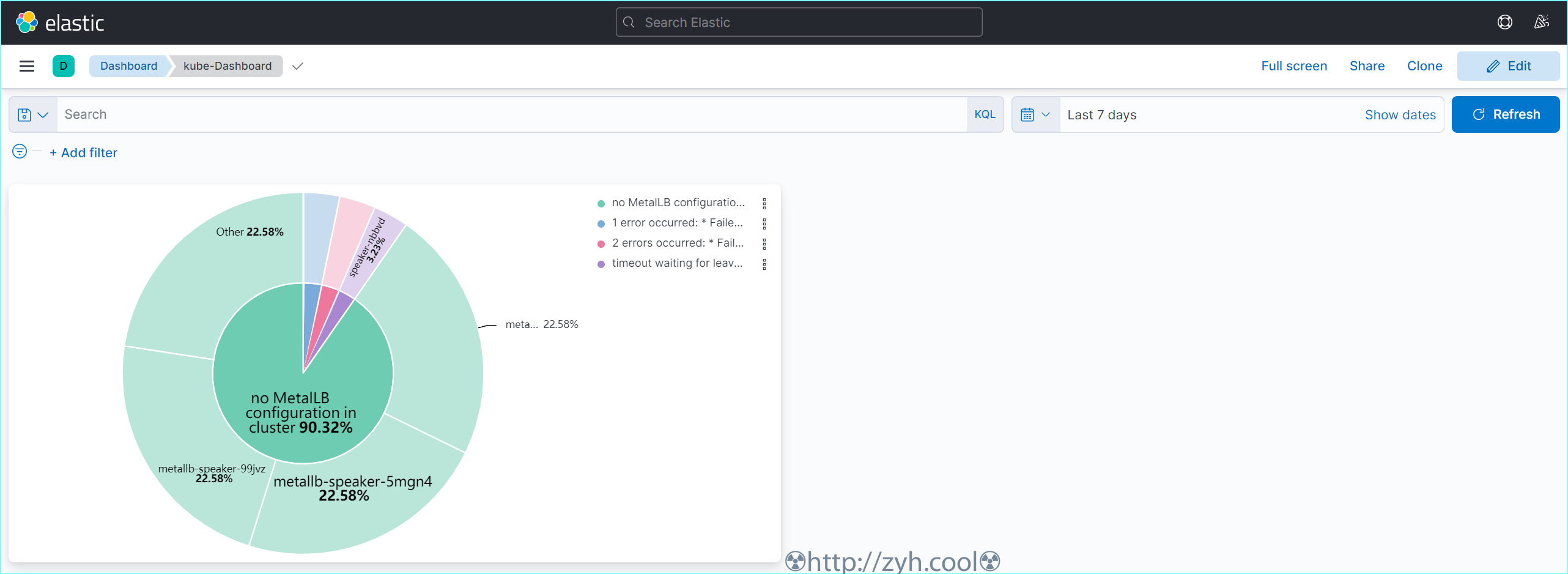
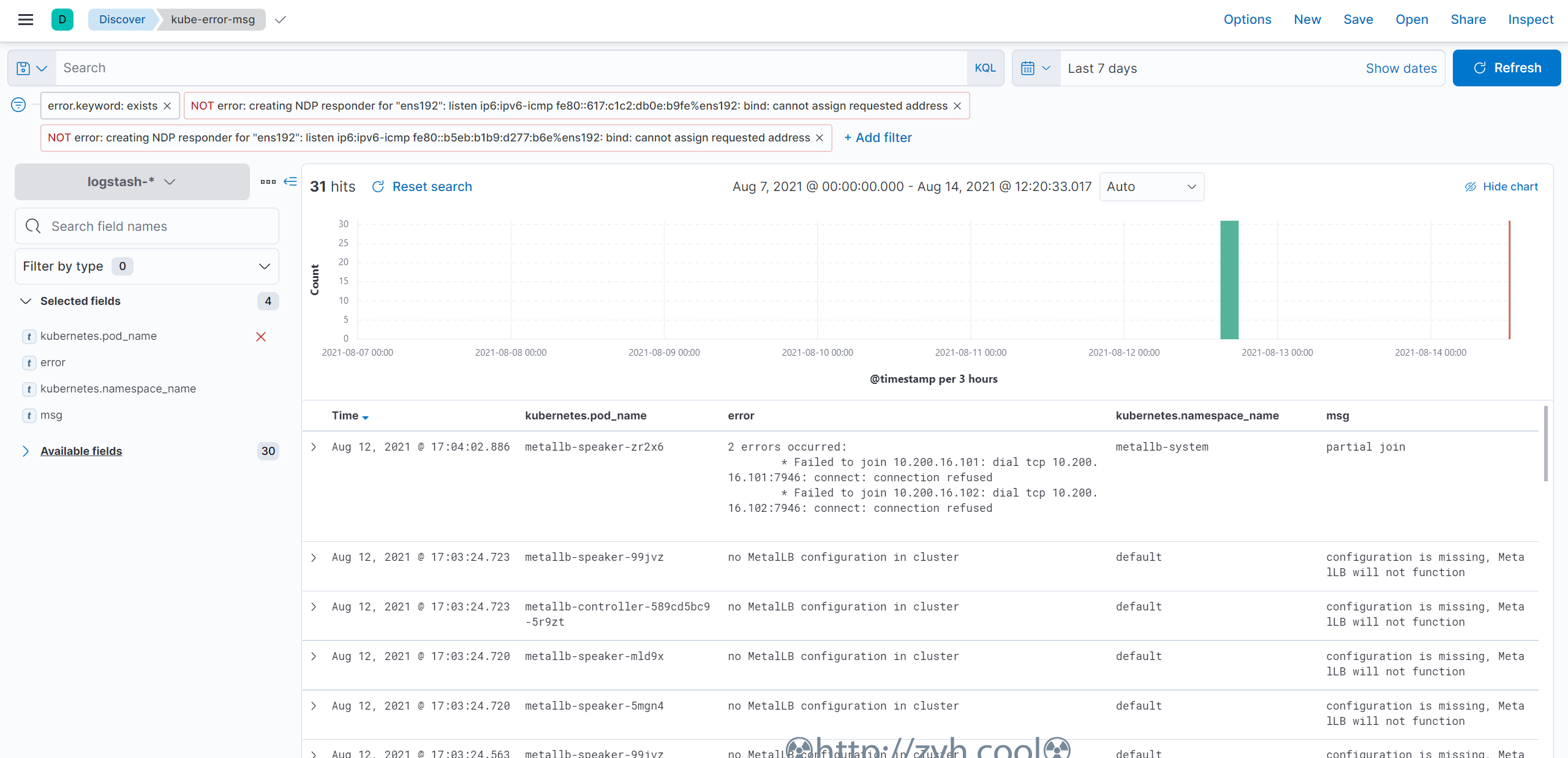
加入kafka
部署
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
helm pull bitnami/kafka --untar --version 12.17.5
cd kafka
配置文件 values-prod.yaml
# values-prod.yaml
## Persistence parameters
##
persistence:
enabled: true
storageClass: "nfs-client"
accessModes:
- ReadWriteOnce
size: 5Gi
## Mount point for persistence
mountPath: /bitnami/kafka
# 配置zk volumes
zookeeper:
enabled: true
persistence:
enabled: true
storageClass: "nfs-client"
accessModes:
- ReadWriteOnce
size: 8Gi
启动
helm upgrade --install kafka -f values-prod.yaml --namespace logging .
校验kafka
kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:2.8.0-debian-10-r0 --namespace logging --command -- sleep infinity
pod/kafka-client created
# 生产者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-producer.sh --broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 --topic test
>hello kafka on k8s
# 消费者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic test --from-beginning
hello kafka on k8s
fluentd添加kafka插件
FROM quay.io/fluentd_elasticsearch/fluentd:v3.2.0
RUN echo "source 'https://mirrors.tuna.tsinghua.edu.cn/rubygems/'" > Gemfile && gem install bundler
RUN gem install fluent-plugin-kafka -v 0.16.1 --no-document
配置fluentd,将output指向kafka
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
......
output.conf: |-
<match **>
@id kafka
@type kafka2
@log_level info
# list of seed brokers
brokers kafka-0.kafka-headless.logging.svc.cluster.local:9092
use_event_time true
# topic settings
topic_key k8slog
default_topic messages # 注意,kafka中消费使用的是这个topic
# buffer settings
<buffer k8slog>
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
</buffer>
# data type settings
<format>
@type json
</format>
# producer settings
required_acks -1
compression_codec gzip
</match>
校验kafka是否有数据
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic messages --from-beginning
{"stream":"stdout","docker":{},"kubernetes":{"container_name":"count","namespace_name":"default","pod_name":"counter","container_image":"busybox:latest","host":"node1","labels":{"logging":"true"}},"message":"43883: Tue Apr 27 12:16:30 UTC 2021\n"}
......
加入logstash
部署
helm pull elastic/logstash --untar --version 7.12.0
cd logstash
配置
# values-prod.yaml
fullnameOverride: logstash
persistence:
enabled: true
logstashConfig:
logstash.yml: |
http.host: 0.0.0.0
# 如果启用了xpack,需要做如下配置
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.hosts: ["http://elasticsearch-client:9200"]
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "ydzsio321"
# 要注意下格式
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
filter {} # 过滤配置(比如可以删除key、添加geoip等等)
output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "ydzsio321" index => "logstash-k8s-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }
volumeClaimTemplate:
accessModes: ["ReadWriteOnce"]
storageClassName: nfs-storage
resources:
requests:
storage: 1Gi
👙stdout { codec => rubydebug } 仅当测试中添加
启动
$ helm upgrade --install logstash -f values-prod.yaml --namespace logging .
校验
kubectl logs -f logstash-0 -n logging
......
{
"docker" => {},
"stream" => "stdout",
"message" => "46921: Tue Apr 27 13:07:15 UTC 2021\n",
"kubernetes" => {
"host" => "node1",
"labels" => {
"logging" => "true"
},
"pod_name" => "counter",
"container_image" => "busybox:latest",
"container_name" => "count",
"namespace_name" => "default"
},
"@timestamp" => 2021-04-27T13:07:15.761Z,
"@version" => "1"
}
最终的工具栈
Fluentd+Kafka+Logstash+Elasticsearch+Kibana
$ kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-client-0 1/1 Running 0 128m
elasticsearch-data-0 1/1 Running 0 128m
elasticsearch-master-0 1/1 Running 0 128m
fluentd-6k52h 1/1 Running 0 61m
fluentd-cw72c 1/1 Running 0 61m
fluentd-dn4hs 1/1 Running 0 61m
kafka-0 1/1 Running 3 134m
kafka-client 1/1 Running 0 125m
kafka-zookeeper-0 1/1 Running 0 134m
kibana-kibana-66f97964b-qqjgg 1/1 Running 0 128m
logstash-0 1/1 Running 0 13m