基本
prometheus 通过k8s的serviceaccount来获取授权,从而在k8s的apiserver那里获取 k8s 指标,指标需要从三个方面获取:
- kubelet 内置的 cadvisor
- kubernetes-apiserver.metrics-server (需要额外安装)
- kube-state-metrics (第三方APP,需要提前自行安装)
而上述三个方面,均需要 prometheus 去访问 k8s apiserver。这里需要提前创建授权token.
- cAdvisor:cAdvisor是Google开源的容器资源监控和性能分析工具,它是专门为容器而生,本身也支持Docker容器,Kubernetes中,我们不需要单独去安装,cAdvisor作为kubelet内置的一部分程序可以直接使用
- kube-state-metrics:通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储
- metrics-server:是一个集群范围内的资源数据局和工具,是Heapster的代替品,同样的,metrics-server也只是显示数据,并不提供数据存储服务。他当前的核心作用是:为HPA等组件提供决策指标支持。也可以将接收到的数据存储到influxdb进行存储,简单来说,如果想基础监控,那么就要安装这个组件
不过kube-state-metrics和metrics-server之前还有很大不同的,二者主要区别如下
1.kube-state-metrics主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等
2.metrics-service主要关注的是资源度量API的实现,比如CPU、文件描述符、内存、请求延时等指标
授权认证
kube-apiserver-client访问证书
💥如果prometheus配置了kubernetes_sd_configs.tls_config.insecure_skip_verify: true,即禁用服务器证书认证,则无需这个步骤。
openssl genrsa -out prometheus.key 2048
openssl req -new -key prometheus.key -out prometheus.csr -subj "/CN=prometheus/O=it"
RequestStr=`cat prometheus.csr | base64 | tr -d "\n"`
# 提交申请到k8s
cat <<EOF | kubectl apply -f -
apiVersion: certificates.k8s.io/v1beta1
kind: CertificateSigningRequest
metadata:
name: prometheus
spec:
groups:
- system:authenticated
request: ${RequestStr}
signerName: kubernetes.io/kube-apiserver-client
usages:
- client auth
EOF
# 如果不出错,可以审批
kubectl certificate approve prometheus
# 导出证书
kubectl get csr prometheus -o jsonpath='{.status.certificate}' | base64 --decode > prometheus.crt
# 检查证书有效期
openssl x509 -in prometheus.crt -noout -dates
保存好证书文件 prometheus.crt,prometheus配置所需
创建服务账户/集群角色/集群角色绑定对象
用于查询k8s资源。
kubectl create ns monitor
prometheus-rabc.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
因prometheus访问k8s需要拿到bearer_token,因此还需要获取服务账户prometheus的Tokens。
获取服务账户prometheus存储Token的secret对象名
➜ kubectl get sa prometheus -n monitor -o jsonpath={'.secrets[0].name'} | more
prometheus-token-2gljj
将Token进行解密
➜ kubectl get secret prometheus-token-2gljj -n monitor -o jsonpath={'.data.token'} | base64 -d > prometheus.bearer_token
保存好解密后的 prometheus.bearer_token,prometheus配置所需
安装Metrics-server
添加 metrics-server https://github.com/kubernetes-sigs/metrics-server#configuration
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 修改metrics-server容器参数部分,添加额外的启动参数(arg)
args:
- --kubelet-preferred-address-types=InternalIP
- --kubelet-insecure-tls
kubectl apply -f components.yaml
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
kubectl top 指令需要指标才能输出
安装kube-state-metrics
部署方式:点我
指标文档:https://github.com/kubernetes/kube-state-metrics/tree/master/docs
# 文件克隆到本地后的列表清单:
➜ standard git:(master) ✗ git clone https://github.com/kubernetes/kube-state-metrics.git
total 20
-rw-r--r-- 1 zyh zyh 381 Mar 12 12:07 cluster-role-binding.yaml
-rw-r--r-- 1 zyh zyh 1744 Mar 12 12:07 cluster-role.yaml
-rw-r--r-- 1 zyh zyh 1134 Mar 12 17:29 deployment.yaml
-rw-r--r-- 1 zyh zyh 197 Mar 12 12:07 service-account.yaml
-rw-r--r-- 1 zyh zyh 410 Mar 12 12:07 service.yaml
可以将项目clone下来,然后根据项目源代码里的Dockerfile来,自行build一个镜像。
ARG GOVERSION=1.17
ARG GOARCH=amd64
FROM golang:${GOVERSION} as builder
ARG GOARCH
ENV GOARCH=${GOARCH}
WORKDIR /go/src/k8s.io/kube-state-metrics/
COPY . /go/src/k8s.io/kube-state-metrics/
RUN make build-local
FROM gcr.io/distroless/static:latest-${GOARCH}
COPY --from=builder /go/src/k8s.io/kube-state-metrics/kube-state-metrics /
USER nobody
ENTRYPOINT ["/kube-state-metrics", "--port=8080", "--telemetry-port=8081"]
EXPOSE 8080 8081
GOARCH指定环境,其余无需修改。
根据情况修改 kube-state-metrics 的 service 对象
集群外的prometheus无法直接访问集群内的kube-state-metrics服务,因此需要暴漏kube-state-metrics。
默认配置里,service对象是ClusterIP,仅针对了集群内部。
- prometheus + 阿里云 ASK
通过内网负载均衡器提供。
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
namespace: kube-system
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-spec: slb.s1.small
service.beta.kubernetes.io/alicloud-loadbalancer-address-type: intranet
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-additional-resource-tags: "project=cms-saas"
spec:
type: LoadBalancer
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics
安装
➜ kubectl apply -f .
检查服务是否正常
curl ip:8080/metrics
遇到的问题
性能不够(250m/512Mi,针对3000+ Job对象),导致接口数据返回过慢,引发prometheus数据采集失败。
配置Prometheus
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
通过kubernetes_sd_configs.role: node发现 kubernetes 的节点上的kubelet地址,并将其作为刮取数据源
通过kubernetes_sd_configs.role: endpoints发现 kubernetes service 对象的 endpoint 地址,从而找到 kube-state-metrics 的外部端点地址。
✨配置里需要将api_server替换成k8s的api_server服务地址.
- job_name: 'k8s-cadvisor' # 抓容器, cadvisor被整合在kubelet中
scheme: https
metrics_path: /metrics
tls_config:
#ca_file: /etc/prometheus/conf/prometheus.crt
insecure_skip_verify: true
bearer_token_file: /etc/prometheus/conf/prometheus.bearer_token
kubernetes_sd_configs:
- role: node
api_server: "https://<api_server_ip>:6443"
tls_config:
#ca_file: /etc/prometheus/conf/prometheus.crt
insecure_skip_verify: true
bearer_token_file: /etc/prometheus/conf/prometheus.bearer_token
relabel_configs:
- action: labelmap # 标签映射:抓取regex正则匹配的标签名,复制为replacement,期间标签值不变(replacement为$1时可以不写)
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
metric_relabel_configs:
- source_labels: [instance]
separator: ;
regex: (.+)
target_label: node
replacement: $1
action: replace
- source_labels: [pod_name] # 兼容老集群,老集群曾用标签 pod_name
separator: ;
regex: (.+)
target_label: pod
replacement: $1
action: replace
- source_labels: [container_name] # 兼容老集群,老集群曾用标签 container_name
separator: ;
regex: (.+)
target_label: container
replacement: $1
action: replace
- job_name: 'kubernetes-apiservers'
scheme: https
tls_config:
#ca_file: /etc/prometheus/conf/prometheus.crt
insecure_skip_verify: true
bearer_token_file: /etc/prometheus/conf/prometheus.bearer_token
kubernetes_sd_configs:
- role: endpoints
api_server: "https://<api_server_ip>:6443"
tls_config:
#ca_file: /etc/prometheus/conf/prometheus.crt
insecure_skip_verify: true
bearer_token_file: /etc/prometheus/conf/prometheus.bearer_token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: "kubernetes-state-metrics" # 抓工作负载资源
scheme: http
tls_config:
#ca_file: /etc/prometheus/conf/prometheus.crt
insecure_skip_verify: true
bearer_token_file: /etc/prometheus/conf/prometheus.bearer_token
kubernetes_sd_configs:
- role: endpoints
api_server: "https://<api_server_ip>:6443"
tls_config:
#ca_file: /etc/prometheus/conf/prometheus.crt
insecure_skip_verify: true
bearer_token_file: /etc/prometheus/conf/prometheus.bearer_token
relabel_configs:
- source_labels: [__meta_kubernetes_service_name] # 将自动发现的endpoint只保留kube-state-metrics
regex: kube-state-metrics
replacement: $1
action: keep
metric_relabel_configs: # 排除部分kube-state-metrics采集项目
- source_labels: [__name__]
regex: "^go_.*|^kube_job_.*" # 如果删除 job 会导致 job 对象监控失败.
action: drop
- source_labels: [pod]
regex: "^无需监控的Pod名称前缀-.*"
action: drop
添加grafana模板
https://grafana.com/grafana/dashboards/13105
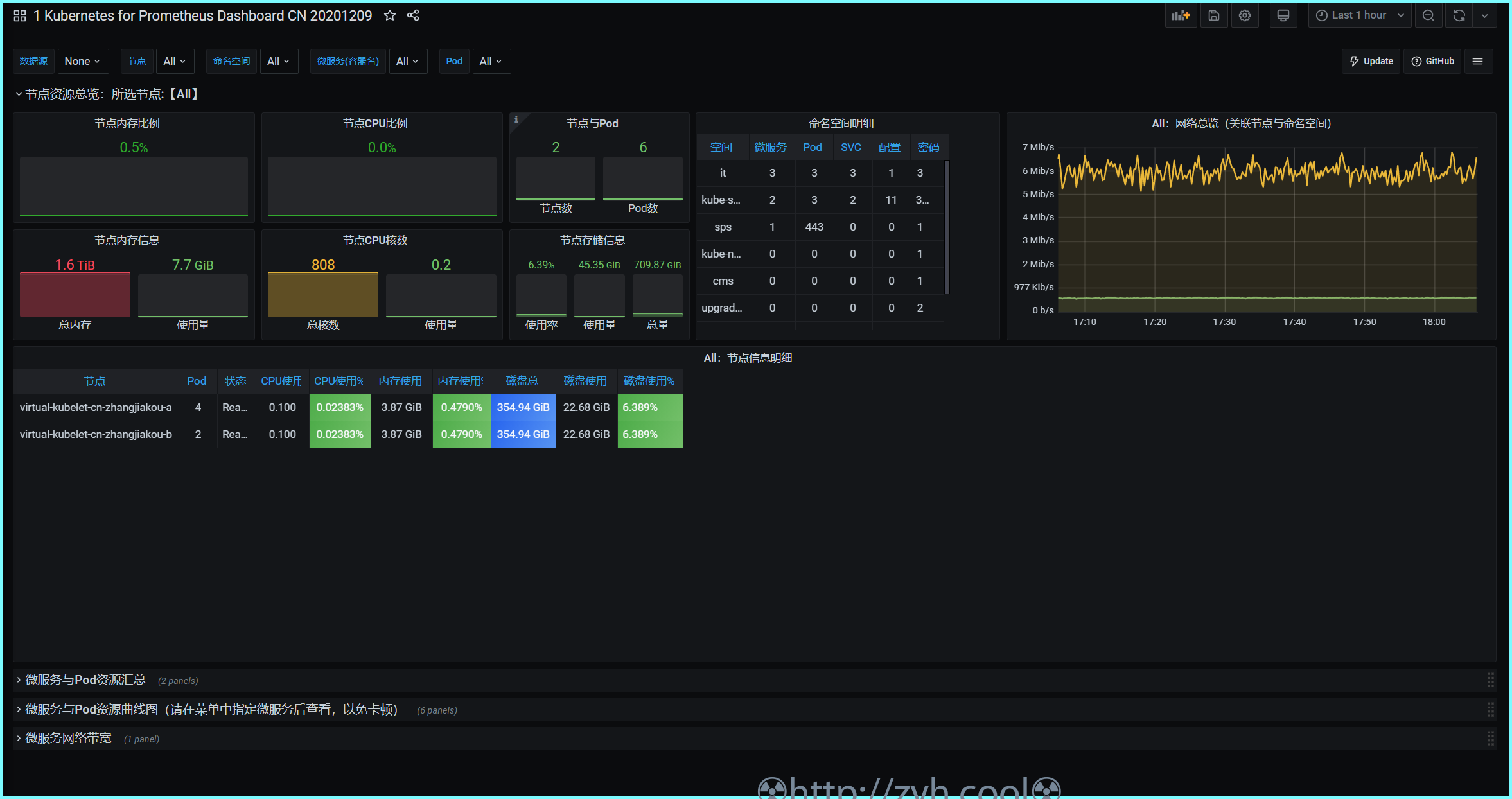
上图是我在阿里云ASK中测试的最终效果图
调整模板
如果你发现模板中,【网络带宽】之类的没有数据,则需要看下此板块SQL里的标签过滤是否有误。
在我的环境里,模板中过滤的 name=‘^k8s_.*’ 无法匹配到Pod。因此删除SQL里的这个过滤即可。
添加预警
需要明确,我们需要监控什么
- k8s本身各组件状态
- 调度了多少个replicas?现在可用的有几个?
- Pod是否启动成功
- Pod重启速率?
groups:
- name: kubernetes
rules:
- alert: kube endpoint down
expr: (up{job="kube-state-metrics"} or up{job="kubernetes-apiservers"}) != 1 #0不正常,1正常
for: 5m #持续时间 ,表示持续5分钟获取不到信息,则触发报警
labels:
severity: error
cluster: k8s
annotations:
summary: "Instance:{{ $labels.instance }}, Job {{ $labels.job }} stop "
sourcedata: '{{ $labels.job }}'
- alert: JobFailed
expr: kube_job_status_failed == 1
for: 5m
labels:
severity: error
cluster: k8s
annotations:
summary: 'Namespace: {{ $labels.namespace }}, Job: {{ $labels.job }} run failed.'
sourcedata: '{{ $labels.job }}'
- alert: PodReady
expr: kube_pod_container_status_ready != 1
for: 5m #Ready持续5分钟,说明启动有问题
labels:
severity: warning
cluster: k8s
annotations:
summary: 'Namespace: {{ $labels.namespace }}, Pod: {{ $labels.pod }} not ready for 5m'
sourcedata: '{{ $labels.job }}'
- alert: PodRestart
expr: kube_pod_container_status_last_terminated_reason == 1 and on(container) rate(kube_pod_container_status_restarts_total[5m]) * 300 > 1
for: 5s
labels:
severity: error
cluster: k8s
annotations:
summary: 'namespace: {{ $labels.namespace }}, pod: {{ $labels.pod }} restart rate > {{ $value }}'
sourcedata: '{{ $labels.job }}'
- alert: Deployment_replicas_available_num_low
expr: kube_deployment_status_replicas - kube_deployment_status_replicas_available > 0
for: 1m
labels:
severity: warning
cluster: k8s
annotations:
summary: 'namespace: {{ $labels.namespace }}, deployment: {{ $labels.deployment }} available low'
sourcedata: '{{ $labels.job }}'
- alert: Deployment_replicas_unavailable
expr: kube_deployment_status_replicas > 0 and kube_deployment_status_replicas_available == 0
for: 1m
labels:
severity: error
cluster: k8s
annotations:
summary: 'namespace: {{ $labels.namespace }}, deployment: {{ $labels.deployment }} unavailable'
sourcedata: '{{ $labels.job }}'