基本
k8s的pod缩放功能,和aws的auto scaling功能是一回事。虽然可能没有aws的auto scaling功能强大。
k8s的pod自动缩放功能称之为HPA(Horizontal Pod Autoscaler),它可以基于设定的cpu阈值,来自动调整控制器中的pod数量。
手动缩放
就是指定一个副本数量
kubectl scale deployment.v1.apps/nginx-dep --replicas=10
自动缩放
自动缩放基于hpa对象资源,hpa需要监控服务,毕竟没有监控指标,就无法根据指标进行自动缩放。
流程图如下:
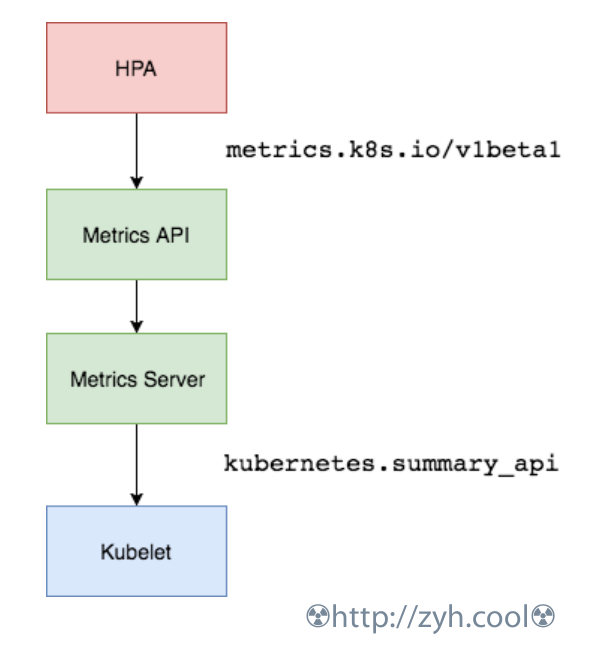
添加监控服务 metrics-server
https://github.com/kubernetes-sigs/metrics-server
metrics 服务器可以通过资源度量值 API 对外提供度量数据,Horizontal Pod Autoscaler 正是根据此 API 来获取度量数据.如果没有此服务,HPA将无法工作.
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
👙默认 metrics-server 的 deployment 无法直接使用, 我们需要添加几个参数, 来禁止 ca 认证和开通 dns
在 deployment.spec.template.spec.containers 中新加入下列配置:
command:
- /metrics-server
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalDNS,InternalIP,ExternalDNS,ExternalIP,Hostname
kubectl apply -f components.yaml
校验
可以看到CPU和内存的指标,就表示工作正常了。
➜ ~ kubectl top pods -n kube-system
NAME CPU(cores) MEMORY(bytes)
coredns-78fcd69978-dt4lx 1m 29Mi
coredns-78fcd69978-nzb7m 1m 31Mi
etcd-k8s01 25m 118Mi
etcd-k8s02 38m 385Mi
etcd-k8s03 27m 325Mi
k8s-logs-4mx8d 1m 46Mi
k8s-logs-csqq4 1m 77Mi
k8s-logs-ctntv 1m 73Mi
k8s-pod-logs-6zgbf 2m 157Mi
k8s-pod-logs-pf669 1m 131Mi
k8s-pod-logs-qnscr 1m 150Mi
kube-apiserver-k8s01 62m 615Mi
kube-apiserver-k8s02 87m 677Mi
kube-apiserver-k8s03 80m 503Mi
kube-controller-manager-k8s01 2m 29Mi
kube-controller-manager-k8s02 15m 130Mi
kube-controller-manager-k8s03 3m 30Mi
kube-flannel-ds-8gk87 1m 23Mi
kube-flannel-ds-9hnrs 2m 28Mi
kube-flannel-ds-rqdm4 2m 24Mi
kube-proxy-9lp9q 1m 31Mi
kube-proxy-rwt48 4m 28Mi
kube-proxy-xlxt6 8m 31Mi
kube-scheduler-k8s01 4m 36Mi
kube-scheduler-k8s02 3m 31Mi
kube-scheduler-k8s03 3m 33Mi
kube-state-metrics-74c958c8bc-nlmcx 2m 19Mi
metrics-server-6bd8d94d7f-shs7n 3m 35Mi
snapshot-controller-0 1m 20Mi
创建测试用例
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
hpa-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
Service 类型通过
spec.selector选择pod
基于CPU指标开启
命令方式:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=5
声明方式:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 5
targetCPUUtilizationPercentage: 50
这里的意思是, cpu 阈值50%, 最小pod数1, 最大pod数5. hpa会将所有pod的平均cpu利用率维持在50%, 并且pod数量在1~5的范围内波动
⚠️只允许拥有一个规则
查看当前cpu使用率
➜ kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 5 1 57m
⚠️如果TARGETS显示unknown没有获取到Deployment的资源利用率,则说明Deployment中没有添加对应的资源限制。
通过busybox以死循环方式访问web服务,快速增加测试服务的cpu使用率
kubectl run -it --rm load-generator --image=busybox /bin/sh
while true; do wget -q -O- http://php-apache; done
=== 会输出大量OK!
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!
在经过一段时间等待后(不会超过1分钟, 默认监控抓取数据间隔时间是1分钟),我们可以看到 pod 数量发生变化
➜ kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 5 1 60m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 5 1 60m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 250%/50% 1 5 1 61m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 250%/50% 1 5 1 61m
➜ kubectl get deployment/php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 5/5 5 5 68m
现在,关闭客户端请求,等待1分钟以上.再次看hpa, 这时候cpu利用率已经下降
➜ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 11%/50% 1 5 5 64m
再看pod数量,它应该已经开始缩减。
缩减并不是在cpu使用率下降之后就立即执行,而是内部有一个算法.它避免因立即执行从而导致资源出现反复波动.
➜ kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 5/5 5 5 70m
➜ kubectl describe deployment/php-apache
Name: php-apache
Namespace: default
CreationTimestamp: Wed, 16 Sep 2020 10:22:32 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: run=php-apache
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: run=php-apache
Containers:
php-apache:
Image: k8s.gcr.io/hpa-example
Port: 80/TCP
Host Port: 0/TCP
Limits:
cpu: 500m
Requests:
cpu: 200m
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetAvailable
Available True MinimumReplicasAvailable
OldReplicaSets: <none>
NewReplicaSet: php-apache-5c4f475bf5 (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 14m deployment-controller Scaled up replica set php-apache-5c4f475bf5 to 4
Normal ScalingReplicaSet 14m deployment-controller Scaled up replica set php-apache-5c4f475bf5 to 5
Normal ScalingReplicaSet 6m50s deployment-controller Scaled down replica set php-apache-5c4f475bf5 to 4
Normal ScalingReplicaSet 4m49s deployment-controller Scaled down replica set php-apache-5c4f475bf5 to 1
常用的也就上面的基于CPU指标
基于其它非资源类型的指标
当前hpa的api版本是autoscaling/v1,它只能抓取cpu指标。
如果你想抓取其它资源指标,例如内存指标(当前也只支持内存),那么需要将版本变更为autoscaling/v2beta2。
✨资源类型的指标名在集群内是统一的,不可变的。
另外,v2 版本还支持非资源类型指标,例如Pods和Object类型。
✨非资源类型指标名是特定于集群的,不是不可变的,且指标数据依赖于额外的监控系统。
最后,autoscaling/v2beta2版本的配置有了一些变化,且可能随时会有新的变化.
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: AverageUtilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue # 当前Pods类型的指标只支持 AverageValue 数值类型
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 10k
上面的例子意思是:
- 保持每个pod的cpu使用率不超过50%,并且每秒能承受1000个数据包。
- 所有位于ingress后面的pod,每秒能处理10000个请求。
💥上面的例子仅表示 type: Object 中从 Ingress 中获取指标 requests-per-second。但不代表 Ingress 有提供指标API。💥
请注意:
- 指标字段targetCPUUtilizationPercentage被metrics数组代替,metrics数组包含了多种度量指标。
- 指标分为:直接资源类 Resource,Pod类 Pods,第三类 Object,非k8s对象类 External,容器资源类 ContainerResource
- 指标分类:
- name 指定指标标识名
- target.type 指定指标【值】类型,例如
AverageValue表示平均值,即每一个pod都需要满足此指标值
⚠️关于Resource类型,要么是cpu,要么是memory,两者应二选一。
基于标签的k8s对象指标
- type: Object
object:
metric:
name: `http_requests`
selector: `verb=GET`
target:
type: AverageValue
averageValue: 30
从监控系统里获取标签verb=GET的值
上述例子的意思是,确保每一个pod都能满足标签为verb=GET的http请求数量。
基于非k8s对象指标
- type: External
external:
metric:
name: queue_messages_ready
selector: "queue=worker_tasks"
target:
type: AverageValue
averageValue: 30
当类型变为External的时候,就可以指定监控系统里存储的其它监控指标。
例如,监控系统从消息队列服务里拿到了消息数量的指标,并附加queue=worker_tasks。那么就可以和上述例子一样,根据消息数量指标进行缩放。
度量
hpa和度量指标API里的数据均使用k8s中称为量纲的特殊整数表示。
量纲的意思就是:
- 数字太小就加上后缀单位m,例如1.5写成1500m。
- 数字刚好就是整数显示。
- 数字大就加上后缀单位,比如k,M。
- 总之没有小数。